Med enkle ord om komplekset: hva er nevrale nettverk? Skrive et feedforward nevralt nettverk fra bunnen av.

Innhold
Hva er et nevralt nettverk?
Som du vet, er hjernen vår en kompleks ting. Koordineringen av arbeidet skjer gjennom nerveceller – nerveceller med grener som strekker seg fra dem. Sammenfletter seg med hverandre, danner nevroner et nevralt nettverk – en intrikat mekanisme som bestemmer hele mangfoldet i den menneskelige psyken. Dette er roten til vår selvbevissthet, følelsen av oss som individer, styrt av våre indre ønsker og ambisjoner.
Hvis det oppstår en funksjonsfeil i arbeidet med nevroner, forandrer personen seg uten anerkjennelse. Avhengig av alvorlighetsgraden av skaden, varierer endringene fra milde tegn på avvikende oppførsel til opphør av kroppens normale funksjon. Hjerneskade er ofte dødelig.
Men i dag vil vi ikke snakke om biologi, fordi ikke bare hjernesystemet vårt kalles nevrale nettverk, men også et komplekst dataprogram med lignende driftsprinsipper. Som grå materie er det fraktal, det vil si at det består av mange enklere programmer som danner en slags symbiose.
Mens det fungerer, lærer nevrale nettverk, får erfaring og blir mer perfekt. Dermed har vi å gjøre med en ekte digital organisme, som er spådd å overgå skaperen en dag.
Hvordan nevrale nettverk dukket opp
Fremveksten av konseptet med kunstige nevrale nettverk dateres tilbake til 40-tallet i forrige århundre. Spesielt er det knyttet til forskere McCulloch og Pitts, som prøvde å simulere hjernens prosesser. De foreslo også ideen om å lage et selvlæringssystem designet for å utføre forskjellige logiske operasjoner. Problemet var at datidens teknologier var langt fra dagens, og oppfinnerne klarte ikke å realisere ideene sine fullt ut.
(Warren McCulloch og Walter Pitts)
Arbeidet deres ble videreført av den kanadiske fysiologen Donald Hebb, og i 1949 ble den første algoritmen for beregning av ANN presentert for verden. I de neste ti årene tjente den som en base for utviklingen av andre forskere, til slutt, i 1958, skapte Frank Rosenblatt parceptronen, en teknologi som etterligner hjernenes arbeid. For sin tid var denne nyheten utrolig. Sovjetiske og amerikanske forskere ble med på arbeidet, som også bidro betydelig til forskningen.
På slutten av XX – begynnelsen av XXI århundre gjorde teknologien et skarpt sprang, som fungerte som et godt incitament for mer intensiv vitenskapelig aktivitet, og i 2007 kom datavitenskapsmann Jeffrey Hinton med en dyp læringsalgoritme for nevrale nettverk, som nå er mye brukt i selvkjørende biler.

(Geoffrey Hinton)
Litt historie
For første gang oppstod konseptet med kunstige nevrale nettverk (ANN) når man prøvde å simulere hjernens prosesser. Det første store gjennombruddet i dette området kan betraktes som opprettelsen av McCulloch-Pitts nevrale nettverksmodell i 1943. Forskere utviklet først en modell av et kunstig nevron. De foreslo også bygging av et nettverk av disse elementene for å utføre logiske operasjoner. Men viktigst av alt, forskere har bevist at et slikt nettverk er i stand til å lære.

Det neste viktige trinnet var utviklingen av Donald Hebb av den første algoritmen for beregning av ANN i 1949, som ble grunnleggende de neste tiårene. I 1958 utviklet Frank Rosenblatt parceptron, et system som etterligner hjernens prosesser. På en gang hadde teknologien ingen analoger og er fortsatt grunnleggende i nevrale nettverk. I 1986 forbedret amerikanske og sovjetiske forskere nesten samtidig, uavhengig av hverandre, den grunnleggende metoden for å lære ut flerlagsperseptronen betydelig. I 2007 gjennomgikk nevrale nettverk en gjenfødelse. Britisk datavitenskapsmann Jeffrey Hinton utviklet først en dybdelæringsalgoritme for flerlags nevrale nettverk, som nå for eksempel brukes til å betjene ubemannede kjøretøy.
Kort om det viktigste
I ordets generelle forstand er nevrale nettverk matematiske modeller som fungerer på prinsippet om nettverk av nerveceller i en dyreorganisme. ANN kan implementeres i både programmerbare og maskinvareløsninger. For å gjøre det lettere å oppfatte kan en nevron forestilles som en slags celle, som har mange inngangshull og en utgang. Hvor mange innkommende signaler som dannes til den utgående, bestemmer beregningsalgoritmen. Effektive verdier blir matet til hver nevroninngang, som deretter forplantes langs interneuronale forbindelser (synopsis). Synapser har en parameter – vekt, på grunn av hvilken inngangsinformasjonen endres når man beveger seg fra en nevron til en annen. Den enkleste måten å forestille seg hvordan nevrale nettverk fungerer, kan representeres av eksemplet på fargeblanding. De blå, grønne og røde nevronene har forskjellige vekter.
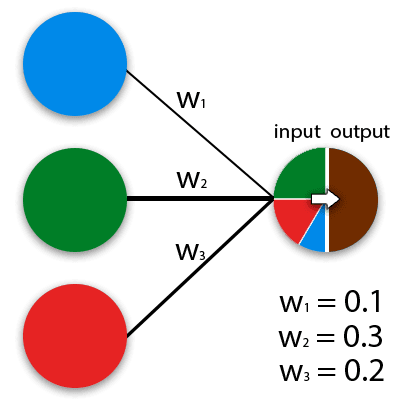
Nevrale nettverket er et system av mange slike nevroner (prosessorer). Separat er disse prosessorene ganske enkle (mye enklere enn en personlig datamaskinprosessor), men når de er koblet til et stort system, er nevroner i stand til å utføre svært komplekse oppgaver.
Avhengig av bruksområde, kan et nevralt nettverk tolkes på forskjellige måter. For eksempel er ANN et mønstergjenkjenningsmetode fra synspunkt maskinlæring. Fra et matematisk synspunkt er dette et multi-parameter problem. Fra cybernetics synspunkt er det en modell for adaptiv kontroll av robotikk. For kunstig intelligens er ANN en grunnleggende komponent for modellering av naturlig intelligens ved bruk av beregningsalgoritmer.
Den største fordelen med nevrale nettverk over konvensjonelle beregningsalgoritmer er deres evne til å lære. I ordets generelle forstand består læring i å finne de riktige koblingskoeffisientene mellom nevroner, samt å generalisere data og identifisere komplekse forhold mellom inngangs- og utgangssignaler. Faktisk betyr vellykket opplæring av et nevralt nettverk at systemet vil være i stand til å identifisere riktig resultat basert på data som ikke er til stede i treningssettet.
Anvendelse av nevrale nettverk
Utvalget av anvendelse av nevrale nettverk er utrolig bredt og er bare begrenset av vår fantasi. La oss liste opp noen av dem:
- Automatiske transportkontrollsystemer. Autopiloter.
- Internettet. Stemmeassistenter, smarte nettlesere, oversettelsesprogrammer.
- Økonomi og næringsliv. Prognoser for valutakurser, moderne regnskapsprogrammer, handelsroboter, risikovurderingsprogrammer, styring av produksjonsmaskiner, kvalitetskontroll, etc.
- Medisin. Moderne metoder for å diagnostisere, analysere effektiviteten av behandlingen, behandle medisinske bilder.
- Robotikk. Ruteplanlegging, tale- og gestgjenkjenning.
- Sikkerhet. Styring av videoovervåkningssystemer og alarmer.
- Dataspill og underholdning. Smarte bots, analytiske programmer for sjakk og andre spill.
- Kunst. Oppretting av malerier, bøker og andre kulturelle gjenstander.

Dagens situasjon
Og uansett hvor lovende denne teknologien ville være, så langt er ANN-er fortsatt veldig langt fra menneskets hjerne og tenkning. Ikke desto mindre brukes nevrale nettverk allerede i mange områder av menneskelig aktivitet. Så langt er de ikke i stand til å ta svært intellektuelle beslutninger, men de er i stand til å erstatte en person der han tidligere var behov for. Blant de mange områdene innen ANN-applikasjon kan man merke seg: opprettelsen av selvlæringssystemer for produksjonsprosesser, ubemannede kjøretøyer, bildegjenkjenningssystemer, intelligente sikkerhetssystemer, roboter, kvalitetsovervåkningssystemer, grensesnitt for taleinteraksjoner, analysesystemer og mye mer. Denne utbredte bruken av nevrale nettverk skyldes blant annet fremveksten av forskjellige måter å akselerere læringen av ANN.
I dag er markedet for nevrale nettverk stort – det er milliarder og milliarder dollar. Som praksis viser, skiller de fleste teknologiene til nevrale nettverk rundt seg lite seg fra hverandre. Imidlertid er bruken av nevrale nettverk en veldig kostbar oppgave, som i de fleste tilfeller bare kan gis av store selskaper. For utvikling, opplæring og testing av nevrale nettverk kreves det stor datakraft, det er åpenbart at store aktører i IT-markedet har nok av dette. Blant de viktigste selskapene som leder utviklingen på dette området er Googles DeepMind-divisjon, Microsoft Research-divisjon, IBM, Facebook og Baidu.
Selvfølgelig er alt dette bra: nevrale nettverk utvikler seg, markedet vokser, men så langt er ikke hovedoppgaven løst. Menneskeheten har ikke klart å skape en teknologi som til og med er nær menneskets hjerne. La oss se på hovedforskjellene mellom den menneskelige hjerne og kunstige nevrale nettverk.
Hvorfor er nevrale nettverk fremdeles langt fra den menneskelige hjerne?
Den viktigste forskjellen, som fundamentalt endrer systemets prinsipp og effektivitet, er forskjellig signaloverføring i kunstige nevrale nettverk og i det biologiske nettverket av nevroner. Faktum er at i ANN overfører nevroner verdier som er reelle verdier, det vil si tall. I den menneskelige hjerne overføres impulser med en fast amplitude, og disse impulsene er nesten øyeblikkelige. Derfor er det en rekke fordeler med det menneskelige nettverket av nevroner.
For det første er kommunikasjonslinjer i hjernen mye mer effektive og økonomiske enn i ANN-er. For det andre sørger impulskretsen for at teknologimplementeringen er enkel: det er nok å bruke analoge kretser i stedet for komplekse beregningsmekanismer. Til slutt er impulsnettverk beskyttet mot akustisk interferens. Effektive tall er utsatt for støy, noe som øker sannsynligheten for feil.
Utsikter for nevrale nettverk
Luddite-bevegelsen begynte tidlig på 1800-tallet. Dette ordet ble brukt for å beskrive mennesker som deltok i protester mot urbanisering. Med industrialiseringen av samfunnet, da maskinverktøy gradvis begynte å erstatte arbeidere, ble mange mennesker utenfor arbeidslivet og var ekstremt misfornøyde med situasjonen. Tenk deg hvilket sjokk de ville ha opplevd hvis de fikk vite at maskinene om et par hundre år vil kunne snakke og til og med bevege seg selvstendig!
I mellomtiden har disse tider kommet, og i dag er det også retrograder som frykter at robotikk og utvikling av teknologi generelt kan spille en grusom vits med mennesker. Tross alt, hvis maskiner allerede er i stand til å utføre så mange oppgaver i dag, vil de i fremtiden besette alle jobber, noe som gjør folk unødvendige. Og denne posisjonen blir bare bekreftet av vurderingene fra eksperter som nå og da forutsier den forestående forsvinningen av et bestemt yrke.
Denne posisjonen har rett til å eksistere, men den er ikke helt korrekt, siden over tid forsvinner ikke bare gamle yrker, men også nye dukker opp. Ja, det er en størrelsesorden mindre gjeter og jegere enn før, men programmerere og markedsførere har dukket opp. På vendepunktene i historien orienterer økonomien seg selv, lukker ut unødvendige og gir sjenerøst de etterspurte.
Den økende innflytelsen fra kunstige nevrale nettverk er åpenbar, og det er sannsynlig at de snart vil være bokstavelig talt overalt, men å være redd for dette betyr å avvise selve menneskets natur, som består i ønsket om oppdagelse og prestasjon.
Opprettelse av nevrale blokker
Først må du bestemme hva de grunnleggende komponentene i et nevralt nettverk – nevroner – er. Nevronen tar inndata, utfører visse matematiske operasjoner med den, og sender deretter ut resultatet. Et nevron med to innganger ser slik ut:
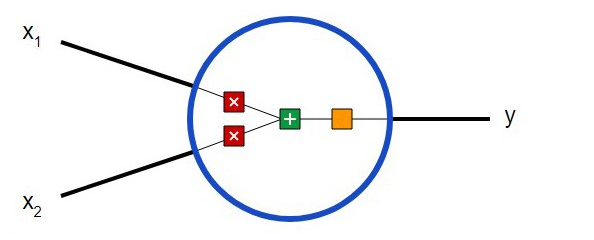
Tre ting skjer her. Først multipliseres hver inngang med vekten (vist i rødt i diagrammet ):
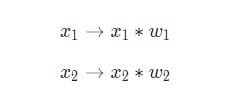
Deretter legges alle vektede innganger sammen med forskyvningen b(vist i grønt i diagrammet ):
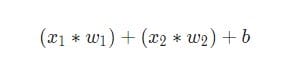
Til slutt overføres beløpet gjennom aktiveringsfunksjonen (markert med gult i diagrammet ):

Aktiveringsfunksjonen brukes til å koble ikke-relaterte innganger til en utgang som har en enkel og forutsigbar form. Som regel tas sigmoidfunksjonen som aktiveringsfunksjonen som brukes :
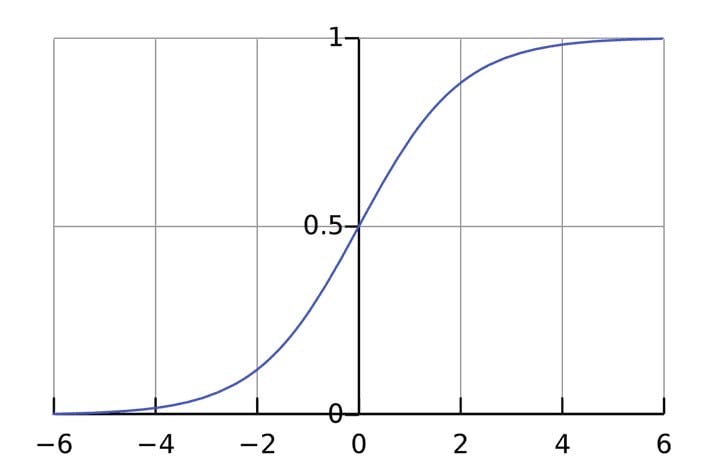
Sigmoid-funksjonen sender bare ut tall i et område (0, 1). Du kan tenke på det som komprimering fra (−∞, +∞)til (0, 1). Store negative tall blir ~0, og store positive tall blir ~1.
Et enkelt eksempel på å jobbe med nevroner i Python
Anta at vi har et nevron med to innganger som bruker en sigmoid-aktiveringsfunksjon og har følgende parametere:
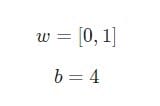
w = [0,1]Er bare en måte å skrive på w1 = 0, w2 = 1i vektorform. La oss tildele en inngang med en verdi til nevronet x = [2, 3]. For en mer kompakt representasjon vil prikkproduktet brukes .
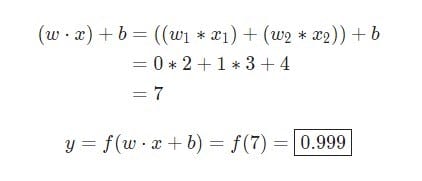
Gitt at inngangen var x = [2, 3], vil utgangen være lik 0.999. Det er alt. Denne prosessen med å sende inngangsdata for å motta utdata kalles feedforward.
Å bygge et nevron fra bunnen av i Python
La oss begynne å implementere nevronet. Dette vil kreve bruk av NumPy. Det er et kraftig beregnings Python-bibliotek som bruker matematiske operasjoner:
|
en 2 3 fire fem 6 7 åtte ni 10 elleve 12 1. 3 fjorten femten seksten 17 atten nitten tjue 21 22 23 24 25 26 27 |
importer nummen som np def sigmoid ( x ) : # Vår aktiveringsfunksjon: f (x) = 1 / (1 + e ^ (- x)) returner 1 / ( 1 + np . exp ( – x ) ) klasse Neuron : def __init__ ( selv , vekter , skjevhet ) : selv . vekter = vekter selv . skjevhet = skjevhet def feedforward ( selv , innganger ) : # Angi vektdata, legg til forskyvning # og påfølgende bruk av aktiveringsfunksjonen totalt = np . dot ( selv . vekter , innganger ) + selv . partiskhet retur sigmoid ( totalt ) vekter = np . matrise ( [ 0 , 1 ] ) # w1 = 0, w2 = 1 skjevhet = 4 # b = 4 n = Neuron ( vekter , skjevhet ) x = np . matrise ( [ 2 , 3 ] ) # x1 = 2, x2 = 3 print ( n . feedforward ( x ) ) # 0.9990889488055994 |
Kjenner du igjen tallene? Dette er det samme eksemplet som ble diskutert tidligere. Svaret du mottok denne gangen er også likt 0.999.
Et eksempel på å samle nevroner i et nevralt nettverk
Et nevralt nettverk er egentlig en gruppe sammenkoblede nevroner. Et enkelt nevralt nettverk ser slik ut:
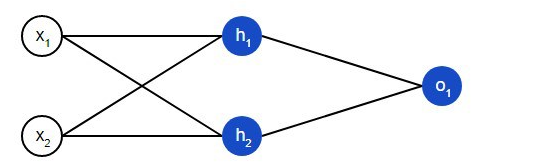
På det innledende laget av nettverket er det to innganger – x1og x2. Det er to nøytroner på det skjulte laget – h1og h2. Det er en nevron på utgangslaget – о1. Merk at inngangene for о1er resultatene h1og h2. Slik er nevrale nettverk bygget.
Et skjult lag er et hvilket som helst lag mellom inngangslaget og utgangslaget, som er henholdsvis det første og det siste laget. Det kan være flere skjulte lag.
Nevrale nettverksopplæring
Utgang ŷ fra et enkelt to-lags nevralt nettverk:
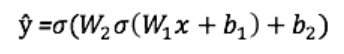
I ovenstående ligning er vektene W og forspenningene b de eneste variablene som påvirker utgangen ŷ.
Naturligvis bestemmer de riktige verdiene for vekter og forspenninger nøyaktigheten av spådommene. Prosessen med å finjustere vekter og forspenninger fra inndata er kjent som neuralt nettverksopplæring.
Hver iterasjon av opplæringsprosessen består av følgende trinn
- beregne den forventede utgangen ŷ kalt forplantning
- oppdatering av vekter og skjevheter kalt backpropagation
Den sekvensielle grafen nedenfor illustrerer prosessen:

Direkte distribusjon
Som vi så i grafen ovenfor, er forplantning bare en enkel beregning, og for et grunnleggende 2-lags nevralt nettverk, blir utgangen fra nevralt nettverk gitt av:
La oss legge til feedforward i Python-koden vår for å gjøre dette. Merk at for enkelhets skyld har vi antatt at forskyvningen er 0.
Vi trenger imidlertid en måte å vurdere «godheten» til prognosene våre, det vil si hvor langt prognosene våre er). Tapsfunksjonen lar oss gjøre nettopp det.
Tap funksjon
Det er mange tapsfunksjoner tilgjengelig, og problemets art bør diktere vårt valg av tapsfunksjon. I denne artikkelen vil vi bruke summen av kvadratene til feilene som tapsfunksjonen.

Summen av kvadrerte feil er gjennomsnittet av forskjellen mellom hver forventet verdi og den faktiske verdien.
Målet med trening er å finne et sett med vekter og skjevheter som minimerer tapfunksjonen.
Forplantning av ryggen
Nå som vi har målt prognosefeil (tap), må vi finne en måte å overføre feilen tilbake og oppdatere vekter og skjevheter.
For å finne ut riktig mengde for å korrigere for vekter og skjevheter, må vi kjenne til derivatet av tapsfunksjonen med hensyn til vekter og skjevheter.
Husk fra analysen at avledningen av en funksjon er tangensen til funksjonens helling.
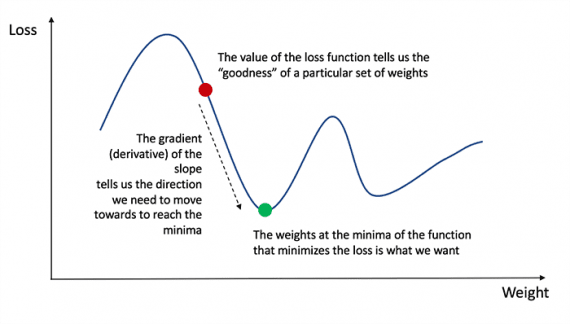
Hvis vi har et derivat, kan vi bare oppdatere vekter og forspenninger ved å øke / redusere dem (se diagrammet ovenfor). Dette kalles gradientnedstigning.
Imidlertid kan vi ikke direkte beregne den avledede av tapsfunksjonen med hensyn til vekter og forspenninger, siden ligningen til tapsfunksjonen ikke inneholder vekter og forspenninger. Derfor trenger vi en kjederegel for å hjelpe til i beregningen.
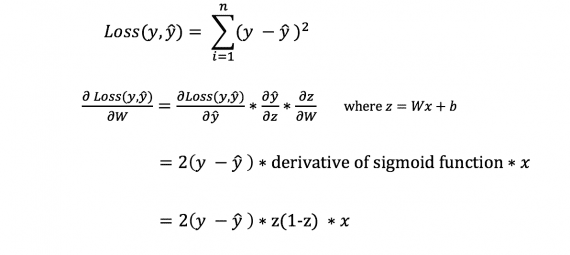
Fuh! Det var tungvint, men det tillot oss å få det vi trenger – den avledede (helling) av tapfunksjonen med hensyn til vektene. Vi kan nå justere vektene deretter.
La oss legge til backpropagation-funksjonen til vår Python-kode:
Delderivater
Delderivater kan beregnes, så det er kjent hva som var bidraget til feilen for hver vekt. Behovet for derivater er åpenbart. Se for deg et nevralt nettverk som prøver å finne den optimale hastigheten for et autonomt kjøretøy. Hvis bilen oppdager at den går raskere eller langsommere enn den nødvendige hastigheten, vil nevrale nettverk endre hastigheten, akselerere eller bremse bilen. Hva akselererer / bremser i dette tilfellet? Hastighetsderivater.
La oss se på behovet for delvis derivater ved hjelp av et eksempel.
Anta at barna blir bedt om å kaste en pil mot et mål, og sikte mot sentrum. Her er resultatene:

Nå, hvis vi finner en generell feil og bare trekker den fra alle vekter, vil vi oppsummere feilene hver har gjort. La oss si at barnet traff for lavt, men vi ber alle barn strebe etter å treffe målet, da vil dette føre til følgende bilde:
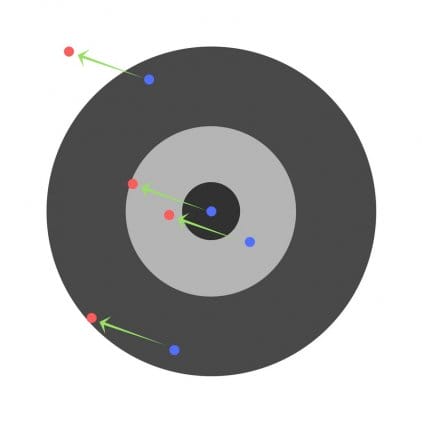
Feilen til flere barn kan avta, men den totale feilen øker fortsatt.
Etter å ha funnet delderivatene, finner vi ut feilene som tilsvarer hver vekt separat. Hvis du selektivt korrigerer vektene, kan du få følgende:
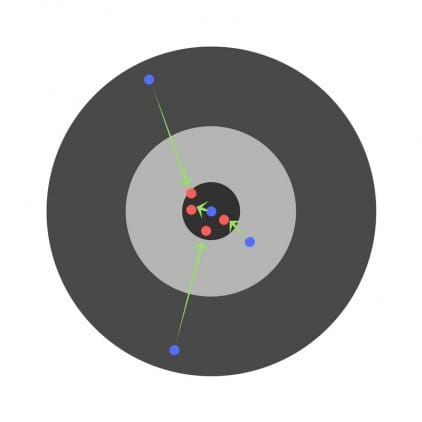
Hyperparametere
Et nevralt nettverk brukes til å automatisere funksjonsvalg, men noen parametere konfigureres manuelt.
Læringsgrad
Læringsgrad er et veldig viktig hyperparameter. Hvis læringsgraden er for lav, selv etter å ha trent nevrale nettverk i lang tid, vil det være langt fra optimale resultater. Resultatene vil se ut slik:
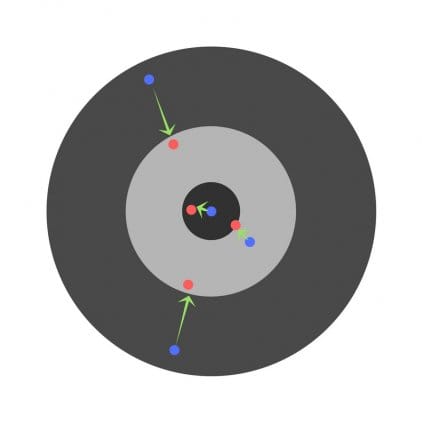
På den annen side, hvis læringsgraden er for høy, vil nettverket svare veldig raskt. Resultatet er følgende:

Dype nevrale nettverk
Dyp læring er en klasse maskinlæringsalgoritmer som lærer å forstå data dypere (mer abstrakt). Populære algoritmer for dyp læring nevrale nettverk er presentert i diagrammet nedenfor.
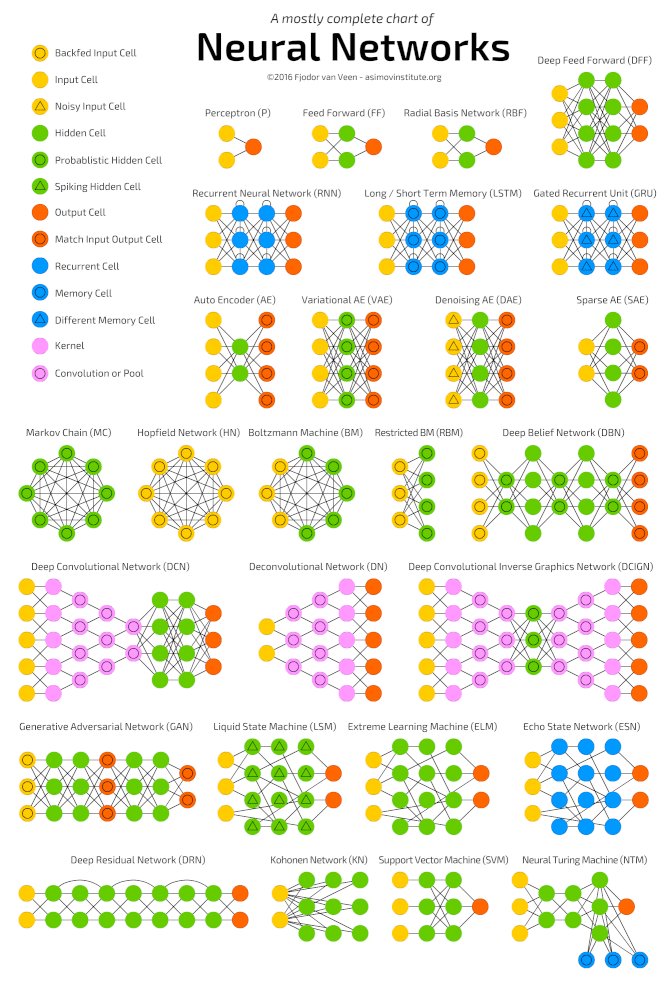
Populære algoritmer for nevrale nettverk (http://www.asimovinstitute.org/neural-network-zoo )
Mer formelt i dyp læring:
- En kaskade (rørledning, som en sekvensielt overført strøm) av en rekke behandlingslag (ikke-lineær) brukes til å trekke ut og transformere funksjoner;
- Basert på studiet av funksjoner (presentasjon av informasjon) i data uten veiledet læring. Funksjonene på høyere nivå (som er i de siste lagene) oppnås fra funksjonene på lavere nivå (som er i lagene til de første lagene);
- Utforsker lagviste visninger som tilsvarer forskjellige abstraksjonsnivåer; nivåer danner et presentasjonshierarki.
Tren det nevrale nettverket ved hjelp av XOR-funksjoner
Hvorfor er XOR-funksjonen så interessant? Rett og slett fordi den ikke kan oppnås av en nevron: 0 ^ 0 = 0, 0 ^ 1 = 1, 1 ^ 0 = 1, 1 ^ 1 = 0. Den oppnås imidlertid enkelt ved å øke antall nevroner. Vi vil prøve å trene et nettverk med 3 nevroner i det skjulte laget og 1 utgang (siden vi bare har en utgang). For å gjøre dette må vi lage en rekke X- og Y-vektorer med treningsdata og selve nevrale nettverk:
// массив входных обучающих векторов Vector[] X = { new Vector(0, 0), new Vector(0, 1), new Vector(1, 0), new Vector(1, 1) }; // массив выходных обучающих векторов Vector[] Y = { new Vector(0.0), // 0 ^ 0 = 0 new Vector(1.0), // 0 ^ 1 = 1 new Vector(1.0), // 1 ^ 0 = 1 new Vector(0.0) // 1 ^ 1 = 0 }; Network network = new Network(new int[]{2, 3, 1}); // создаём сеть с двумя входами, тремя нейронами в скрытом слое и одним выходом Deretter begynner vi å trene med følgende parametere: læringsrate – 0,5, antall epoker – 100000, feilverdi – 1e-7:
network.Train(X, Y, 0.5, 1e-7, 100000); // запускаем обучение сети Etter trening, la oss se på resultatene ved å utføre et direkte pass for alle elementene:
for (int i = 0; i Opptakskilde: lastici.ru