En palabras simples sobre el complejo: ¿qué son las redes neuronales? Escribir una red neuronal feedforward desde cero.

Contenido
¿Qué es una red neuronal?
Como saben, nuestro cerebro es algo complejo. La coordinación de su trabajo se produce a través de neuronas, células nerviosas con ramas que se extienden desde ellas. Al entrelazarse entre sí, las neuronas forman una red neuronal, un intrincado mecanismo que determina toda la diversidad de la psique humana. Esta es la raíz de nuestra autoconciencia, el sentimiento de nosotros como individuos, guiados por nuestros deseos y aspiraciones interiores.
Si ocurre un mal funcionamiento en el trabajo de las neuronas, la persona cambia más allá del reconocimiento. Dependiendo de la gravedad de la lesión, los cambios van desde signos leves de comportamiento desviado hasta el cese del funcionamiento normal del cuerpo. El daño cerebral suele ser fatal.
Pero hoy no hablaremos de biología, porque no solo el sistema de nuestro cerebro se llama redes neuronales, sino también un complejo programa informático con principios operativos similares. Como la materia gris, es fractal, es decir, consta de muchos programas más simples que forman una especie de simbiosis.
Mientras funciona, la red neuronal aprende, gana experiencia y se vuelve más perfecta. Así, estamos ante un organismo digital real, que se prevé que algún día supere a su creador.
Cómo aparecieron las redes neuronales
La aparición del concepto de redes neuronales artificiales se remonta a los años 40 del siglo anterior. En particular, está asociado con los científicos McCulloch y Pitts, que intentaron simular los procesos del cerebro. También propusieron la idea de crear un sistema de autoaprendizaje diseñado para realizar diversas operaciones lógicas. El problema era que las tecnologías de esa época estaban lejos de las de hoy, y los inventores no lograron materializar plenamente sus ideas.
(Warren McCulloch y Walter Pitts)
Su trabajo fue continuado por el fisiólogo canadiense Donald Hebb, y en 1949 se presentó al mundo el primer algoritmo para calcular ANN. Durante los siguientes 10 años, sirvió de base para el desarrollo de otros científicos, hasta que, finalmente, en 1958, Frank Rosenblatt creó el parceptron, una tecnología que imita el trabajo de nuestro cerebro. Para su época, esta novedad fue increíble. Científicos soviéticos y estadounidenses se unieron al trabajo, quienes también hicieron una contribución significativa a la investigación.
A finales del siglo XX y principios del siglo XXI, la tecnología dio un gran salto, lo que sirvió como un buen incentivo para una actividad científica más intensiva, y en 2007, el científico informático Jeffrey Hinton ideó un algoritmo de aprendizaje profundo para redes neuronales, que ahora se utiliza ampliamente. en vehículos autónomos.

(Geoffrey Hinton)
Un poco de historia
Por primera vez, el concepto de redes neuronales artificiales (ANN) surgió al intentar simular los procesos del cerebro. El primer gran avance en esta área puede considerarse la creación del modelo de red neuronal McCulloch-Pitts en 1943. Los científicos desarrollaron por primera vez un modelo de neurona artificial. También propusieron la construcción de una red de estos elementos para realizar operaciones lógicas. Pero lo más importante es que los científicos han demostrado que dicha red es capaz de aprender.

El siguiente paso importante fue el desarrollo por Donald Hebb del primer algoritmo para computar ANN en 1949, que se convirtió en fundamental durante las siguientes décadas. En 1958, Frank Rosenblatt desarrolló el parceptron, un sistema que imita los procesos del cerebro. En un momento, la tecnología no tenía análogos y sigue siendo fundamental en las redes neuronales. En 1986, casi simultáneamente, independientemente unos de otros, los científicos estadounidenses y soviéticos mejoraron significativamente el método fundamental de enseñar el perceptrón multicapa. En 2007, las redes neuronales experimentaron un renacimiento. El científico informático británico Jeffrey Hinton desarrolló por primera vez un algoritmo de aprendizaje profundo para redes neuronales multicapa, que ahora, por ejemplo, se utiliza para operar vehículos no tripulados.
Brevemente sobre los principales
En el sentido general de la palabra, las redes neuronales son modelos matemáticos que funcionan según el principio de redes de células nerviosas en un organismo animal. Las ANN se pueden implementar en soluciones tanto programables como de hardware. Para facilitar la percepción, una neurona se puede representar como una determinada célula, que tiene muchos orificios de entrada y un orificio de salida. El número de señales entrantes que se transforman en salientes determina el algoritmo de cálculo. Los valores efectivos se alimentan a cada entrada de neurona, que luego se propagan a lo largo de las conexiones interneuronales (sinopsis). Las sinapsis tienen un parámetro: el peso, por lo que la información de entrada cambia cuando se pasa de una neurona a otra. La forma más sencilla de imaginar cómo funcionan las redes neuronales puede representarse con el ejemplo de la mezcla de colores. Las neuronas azul, verde y roja tienen diferentes pesos.
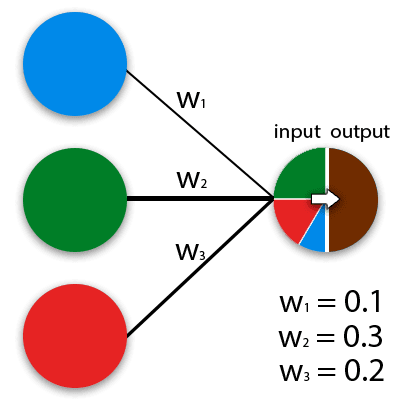
La red neuronal en sí misma es un sistema de muchas de estas neuronas (procesadores). Individualmente, estos procesadores son bastante simples (mucho más simples que un procesador de computadora personal), pero cuando se conectan a un sistema grande, las neuronas son capaces de realizar tareas muy complejas.
Dependiendo del área de aplicación, una red neuronal se puede interpretar de diferentes formas, por ejemplo, desde el punto de vista del aprendizaje automático, una RNA es un método de reconocimiento de patrones. Desde un punto de vista matemático, este es un problema de múltiples parámetros. Desde el punto de vista de la cibernética, es un modelo de control adaptativo de la robótica. Para la inteligencia artificial, ANN es un componente fundamental para modelar la inteligencia natural utilizando algoritmos computacionales.
La principal ventaja de las redes neuronales sobre los algoritmos de cálculo convencionales es su capacidad para aprender. En el sentido general de la palabra, aprender consiste en encontrar los coeficientes de acoplamiento correctos entre neuronas, así como en generalizar datos e identificar dependencias complejas entre señales de entrada y salida. De hecho, el entrenamiento exitoso de una red neuronal significa que el sistema podrá identificar el resultado correcto basándose en datos que no están presentes en el conjunto de entrenamiento.
Aplicación de redes neuronales
El rango de aplicación de las redes neuronales es increíblemente amplio y solo está limitado por nuestra imaginación. Enumeremos algunos de ellos:
- Sistemas de control de transporte automático. Pilotos automáticos.
- La Internet. Asistentes de voz, navegadores inteligentes, programas de traducción.
- Economía y empresa. Previsión de tipos de cambio, programas de contabilidad modernos, robots comerciales, programas de evaluación de riesgos, gestión de máquinas de producción, control de calidad, etc.
- Medicamento. Métodos modernos de diagnóstico, análisis de la efectividad del tratamiento, procesamiento de imágenes médicas.
- Robótica. Planificación de rutas, reconocimiento de voz y gestos.
- Seguridad. Gestión de sistemas de videovigilancia y alarma.
- Juegos de ordenador y entretenimiento. Bots inteligentes, programas analíticos para ajedrez y otros juegos.
- Arte. Creación de pinturas, libros y otros artefactos culturales.

Situación actual
Y no importa cuán prometedora sea esta tecnología, hasta ahora las RNA todavía están muy lejos de las capacidades del cerebro y el pensamiento humanos. Sin embargo, las redes neuronales ya se están utilizando en muchas áreas de la actividad humana. Hasta ahora, no pueden tomar decisiones altamente intelectuales, pero pueden reemplazar a una persona donde antes se necesitaba. Entre las numerosas áreas de aplicación de la ANN, se pueden destacar: la creación de sistemas de autoaprendizaje de procesos productivos, vehículos no tripulados, sistemas de reconocimiento de imágenes, sistemas de seguridad inteligente, robótica, sistemas de monitoreo de calidad, interfaces de interacción de voz, sistemas de analítica y mucho más. Este uso generalizado de las redes neuronales, entre otras cosas, se debe a la aparición de diversas formas de acelerar el aprendizaje de las redes neuronales nerviosas.
Hoy en día, el mercado de las redes neuronales es enorme: miles de millones y miles de millones de dólares. Como muestra la práctica, la mayoría de las tecnologías de redes neuronales de todo el mundo difieren poco entre sí. Sin embargo, el uso de redes neuronales es una empresa muy costosa que, en la mayoría de los casos, solo pueden afrontar las grandes empresas. Para el desarrollo, entrenamiento y prueba de redes neuronales, se requiere una gran potencia informática, es obvio que los grandes actores del mercado de TI tienen suficiente de esto. Entre las principales empresas que lideran el desarrollo en esta área se encuentran Google DeepMind, Microsoft Research, IBM, Facebook y Baidu.
Por supuesto, todo esto es bueno: las redes neuronales se están desarrollando, el mercado está creciendo, pero hasta ahora la tarea principal no se ha resuelto. La humanidad no ha logrado crear una tecnología que se acerque en capacidades al cerebro humano. Echemos un vistazo a las principales diferencias entre el cerebro humano y las redes neuronales artificiales.
¿Por qué las redes neuronales todavía están lejos del cerebro humano?
La diferencia más importante, que cambia fundamentalmente el principio y la eficiencia del sistema, es la diferente transmisión de señales en las redes neuronales artificiales y en la red biológica de neuronas. El caso es que en la RNA las neuronas transmiten valores que son valores reales, es decir, números. En el cerebro humano se transmiten impulsos con una amplitud fija, y estos impulsos son casi instantáneos. Por lo tanto, existen varias ventajas para la red humana de neuronas.
Primero, las líneas de comunicación en el cerebro son mucho más eficientes y económicas que en las RNA. En segundo lugar, el circuito de impulsos asegura la simplicidad de la implementación de la tecnología: basta con utilizar circuitos analógicos en lugar de complejos mecanismos computacionales. En última instancia, las redes de impulsos están protegidas de las interferencias acústicas. Los números efectivos están sujetos a ruido, lo que aumenta la probabilidad de errores.
Perspectivas de las redes neuronales
El movimiento ludita comenzó a principios del siglo XIX. Esta palabra se usó para describir a las personas que participaban en protestas contra la urbanización. Con la industrialización de la sociedad, cuando las máquinas-herramienta comenzaron a reemplazar gradualmente a los trabajadores, muchas personas se quedaron sin trabajo y extremadamente insatisfechas con su situación. ¡Imagínense el impacto que habrían experimentado si supieran que en un par de cientos de años las máquinas podrán hablar e incluso moverse de forma independiente!
Mientras tanto, estos tiempos han llegado, y hoy también hay retrogrados que temen que la robótica y el desarrollo de la tecnología en general puedan jugar una broma cruel con la gente. Después de todo, si las máquinas ya son capaces de realizar tantas tareas en la actualidad, en el futuro ocuparán todos los trabajos, lo que hará que las personas sean innecesarias. Y esta posición solo la confirman las valoraciones de expertos que de vez en cuando predicen la inminente desaparición de una determinada profesión.
Este puesto tiene derecho a existir, pero no es del todo correcto, ya que con el tiempo no solo desaparecen las profesiones antiguas, sino que también aparecen otras nuevas. Sí, hay un orden de magnitud menos pastores y cazadores que antes, pero han aparecido programadores y comercializadores. En momentos decisivos de la historia, la economía se reorienta, eliminando lo innecesario y dotando generosamente a los demandados.
La creciente influencia de las redes neuronales artificiales es obvia, y es probable que pronto estén literalmente en todas partes, pero tener miedo de esto significa rechazar la propia naturaleza humana, que consiste en el deseo de descubrimiento y logro.
Creación de bloques neuronales.
Primero, debe decidir cuáles son los componentes básicos de una red neuronal, las neuronas. La neurona toma datos de entrada, realiza ciertas operaciones matemáticas con ellos y luego genera el resultado. Una neurona con dos entradas se ve así:
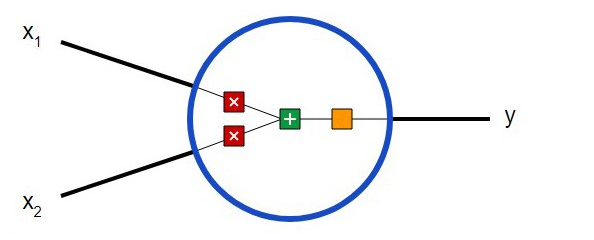
Aquí están pasando tres cosas. Primero, cada entrada se multiplica por el peso (en el diagrama está marcado en rojo ):
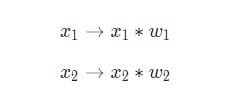
Luego, todas las entradas ponderadas se suman junto con el desplazamiento b(indicado en verde en el diagrama ):
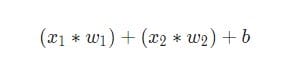
Finalmente, la cantidad se transfiere a través de la función de activación (marcada en amarillo en el diagrama ):

La función de activación se utiliza para conectar entradas no relacionadas a una salida que tiene una forma simple y predecible. Como regla general, la función sigmoidea se toma como la función de activación utilizada :
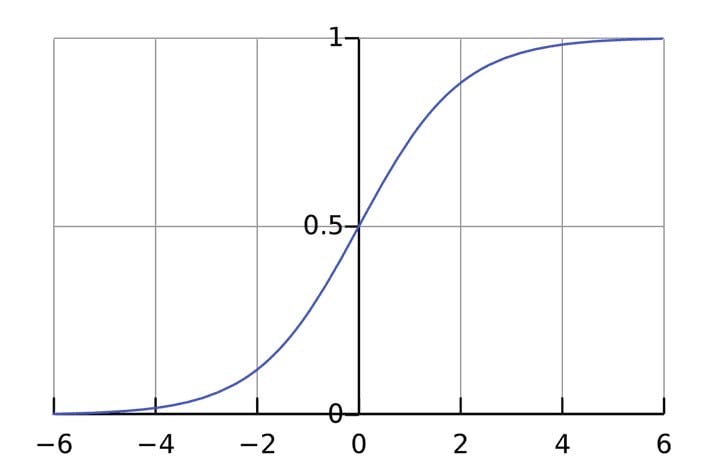
La función sigmoidea solo genera números en un rango (0, 1). Puede pensar en ello como una compresión de (−∞, +∞)a (0, 1). Se vuelven grandes números negativos ~0y grandes números positivos ~1.
Un ejemplo simple de trabajar con neuronas en Python
Supongamos que tenemos una neurona con dos entradas que usa una función de activación sigmoidea y tiene los siguientes parámetros:
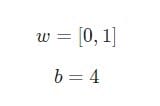
w = [0,1]Es solo una forma de escribir w1 = 0, w2 = 1en forma vectorial. Asignemos una entrada con un valor a la neurona x = [2, 3]. Para una representación más compacta, se utilizará el producto escalar.
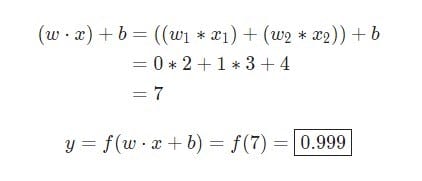
Dado que la entrada fue x = [2, 3], la salida será igual 0.999. Eso es todo. Este proceso de pasar los datos de entrada para recibir la salida se denomina feedforward.
Construyendo una neurona desde cero en Python
Comencemos a implementar la neurona. Esto requerirá el uso de NumPy. Es una poderosa biblioteca computacional de Python que usa operaciones matemáticas:
|
uno 2 3 cuatro cinco 6 7 ocho nueve 10 once 12 13 catorce quince dieciséis 17 Dieciocho diecinueve veinte 21 22 23 24 25 26 27 |
importar numpy como np def sigmoide ( x ) : # Nuestra función de activación: f (x) = 1 / (1 + e ^ (- x)) return 1 / ( 1 + np . exp ( – x ) ) clase Neuron : def __init__ ( self , ponderaciones , sesgo ) : yo . pesos = pesos yo . sesgo = sesgo def feedforward ( auto , entradas ) : # Ingrese datos de peso, agregue compensación # y posterior uso de la función de activación total = np . dot ( auto . pesos , entradas ) + auto . parcialidad volver sigmoidea ( total ) pesos = np . matriz ( [ 0 , 1 ] ) # w1 = 0, w2 = 1 sesgo = 4 # b = 4 n = Neurona ( pesos , sesgo ) x = np . matriz ( [ 2 , 3 ] ) # x1 = 2, x2 = 3 print ( n . feedforward ( x ) ) # 0.9990889488055994 |
¿Reconoces los números? Este es el mismo ejemplo discutido anteriormente. La respuesta recibida esta vez también es igual 0.999.
Un ejemplo de recolección de neuronas en una red neuronal
Una red neuronal es esencialmente un grupo de neuronas interconectadas. Una red neuronal simple se ve así:
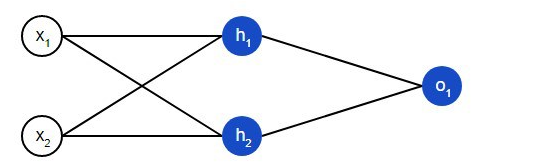
En la capa introductoria de la red, hay dos entradas: x1y x2. Hay dos neutrones en la capa oculta h1y h2. Hay una neurona en la capa de salida – о1. Tenga en cuenta que las entradas para о1son resultados de salida h1y h2. Así es como se construye la red neuronal.
Una capa oculta es cualquier capa entre la capa de entrada y la capa de salida, que son la primera y la última capa, respectivamente. Puede haber varias capas ocultas.
Entrenamiento de redes neuronales
Salida ŷ de una red neuronal simple de dos capas:
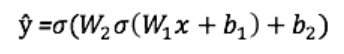
En la ecuación anterior, los pesos W y los sesgos b son las únicas variables que afectan la salida ŷ.
Naturalmente, los valores correctos para los pesos y los sesgos determinan la precisión de las predicciones. El proceso de ajuste fino de ponderaciones y sesgos de los datos de entrada se conoce como entrenamiento de redes neuronales.
Cada iteración del proceso de formación consta de los siguientes pasos
- calcular la salida prevista ŷ denominada propagación hacia adelante
- Actualización de ponderaciones y sesgos denominada retropropagación.
El siguiente gráfico secuencial ilustra el proceso:

Distribución directa
Como vimos en el gráfico anterior, la propagación hacia adelante es solo un cálculo simple, y para una red neuronal básica de 2 capas, la salida de la red neuronal viene dada por:
Agreguemos un avance a nuestro código Python para hacer esto. Tenga en cuenta que, para simplificar, hemos asumido que las compensaciones son 0.
Sin embargo, necesitamos una forma de evaluar la «bondad» de nuestros pronósticos, es decir, qué tan lejos están nuestros pronósticos). La función de pérdida nos permite hacer precisamente eso.
Función de pérdida
Hay muchas funciones de pérdida disponibles, y la naturaleza de nuestro problema debería dictar nuestra elección de función de pérdida. En este artículo, usaremos la suma de los cuadrados de los errores como función de pérdida.

La suma de los errores al cuadrado es el promedio de la diferencia entre cada valor predicho y el valor real.
El objetivo del entrenamiento es encontrar un conjunto de pesos y sesgos que minimice la función de pérdida.
Propagación hacia atrás
Ahora que hemos medido nuestro error de pronóstico (pérdidas), necesitamos encontrar una manera de propagar el error y actualizar nuestros pesos y sesgos.
Para averiguar la cantidad apropiada a corregir por ponderaciones y sesgos, necesitamos conocer la derivada de la función de pérdida con respecto a las ponderaciones y sesgos.
Recuerde del análisis que la derivada de una función es la tangente de la pendiente de la función.
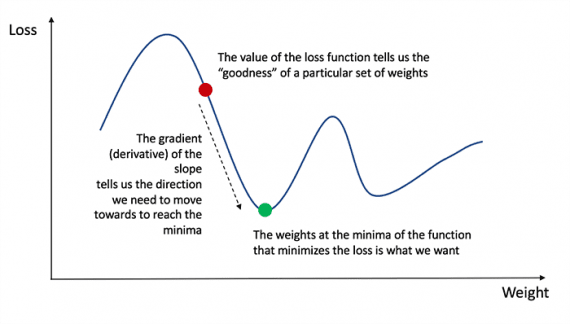
Si tenemos una derivada, simplemente podemos actualizar los pesos y los sesgos incrementándolos / disminuyéndolos (ver diagrama anterior). A esto se le llama descenso de gradiente.
Sin embargo, no podemos calcular directamente la derivada de la función de pérdida con respecto a los pesos y sesgos, ya que la ecuación de la función de pérdida no contiene pesos ni sesgos. Por lo tanto, necesitamos una regla de la cadena para ayudar en el cálculo.
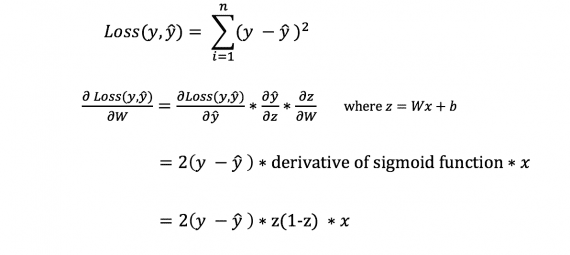
¡Fuh! Era engorroso, pero nos permitió obtener lo que necesitamos: la derivada (pendiente) de la función de pérdida con respecto a los pesos. Ahora podemos ajustar los pesos en consecuencia.
Agreguemos la función de retropropagación a nuestro código Python:
Derivadas parciales
Se pueden calcular derivadas parciales, por lo que se sabe cuál fue la contribución al error para cada peso. La necesidad de derivados es obvia. Imagine una red neuronal que intenta encontrar la velocidad óptima para un vehículo autónomo. Si el automóvil detecta que va más rápido o más lento que la velocidad requerida, la red neuronal cambiará la velocidad, acelerando o desacelerando el automóvil. ¿Qué está acelerando / desacelerando al mismo tiempo? Derivadas de velocidad.
Veamos la necesidad de derivadas parciales con un ejemplo.
Suponga que se les pide a los niños que lancen un dardo a un objetivo mientras apuntan al centro. Aquí están los resultados:

Ahora, si encontramos un error general y simplemente lo restamos de todos los pesos, resumiremos los errores cometidos por cada uno. Entonces, digamos que el niño golpeó demasiado bajo, pero les pedimos a todos los niños que se esfuercen por golpear el objetivo, entonces esto conducirá a la siguiente imagen:
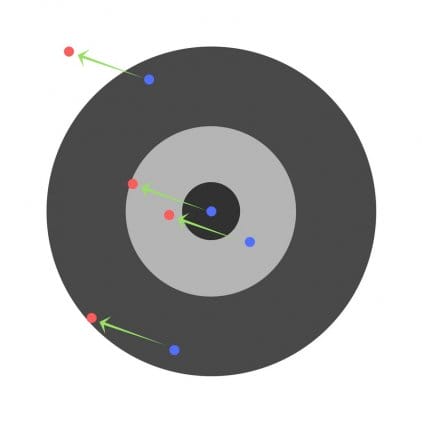
El error de varios niños puede disminuir, pero el error total sigue aumentando.
Habiendo encontrado las derivadas parciales, averiguamos los errores correspondientes a cada peso por separado. Si corrige selectivamente los pesos, puede obtener lo siguiente:
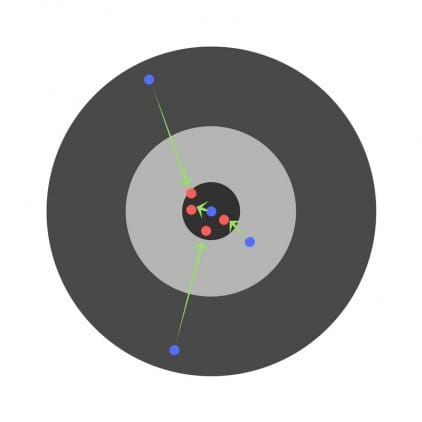
Hiperparámetros
Se utiliza una red neuronal para automatizar la selección de características, pero algunos parámetros se configuran manualmente.
Tasa de aprendizaje
La tasa de aprendizaje es un hiperparámetro muy importante. Si la tasa de aprendizaje es demasiado baja, incluso después de entrenar la red neuronal durante mucho tiempo, estará lejos de obtener resultados óptimos. Los resultados se verán así:
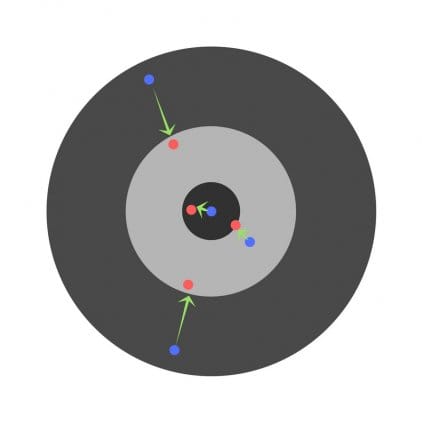
Por otro lado, si la tasa de aprendizaje es demasiado alta, la red responderá muy rápidamente. El resultado es el siguiente:

Redes neuronales profundas
El aprendizaje profundo es una clase de algoritmos de aprendizaje automático que aprenden a comprender los datos de manera más profunda (de manera más abstracta). Los algoritmos populares para redes neuronales de aprendizaje profundo se presentan en el siguiente diagrama.
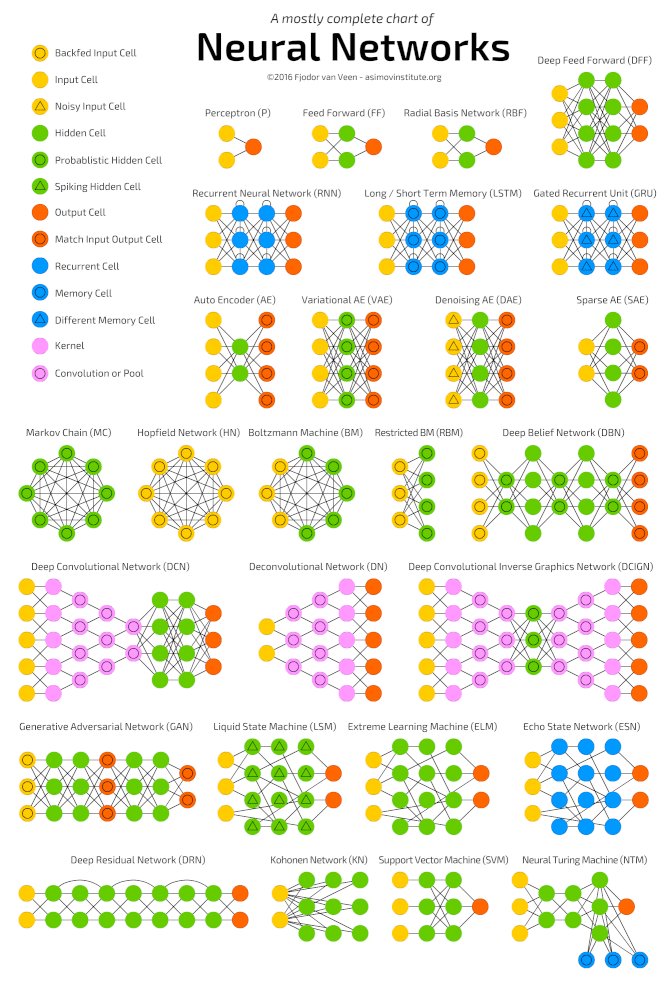
Algoritmos de redes neuronales populares (http://www.asimovinstitute.org/neural-network-zoo )
Más formalmente en aprendizaje profundo:
- Se utiliza una cascada (canalización, como un flujo transmitido secuencialmente) de una pluralidad de capas de procesamiento (no lineales) para extraer y transformar características;
- Basado en el estudio de características (presentación de información) en datos sin aprendizaje supervisado. Las funciones de nivel superior (que están en las últimas capas) se obtienen de las funciones de nivel inferior (que están en las capas de las capas iniciales);
- Explora vistas en capas que corresponden a diferentes niveles de abstracción; Los niveles forman una jerarquía de presentación.
Entrene la red neuronal usando funciones XOR
¿Por qué es tan interesante la función XOR? Simplemente porque no puede ser obtenido por una neurona: 0 ^ 0 = 0, 0 ^ 1 = 1, 1 ^ 0 = 1, 1 ^ 1 = 0. Sin embargo, se obtiene fácilmente aumentando el número de neuronas. Intentaremos entrenar una red con 3 neuronas en la capa oculta y 1 salida (ya que solo tenemos una salida). Para hacer esto, necesitamos crear una matriz de vectores X e Y con datos de entrenamiento y la propia red neuronal:
// массив входных обучающих векторов Vector[] X = { new Vector(0, 0), new Vector(0, 1), new Vector(1, 0), new Vector(1, 1) }; // массив выходных обучающих векторов Vector[] Y = { new Vector(0.0), // 0 ^ 0 = 0 new Vector(1.0), // 0 ^ 1 = 1 new Vector(1.0), // 1 ^ 0 = 1 new Vector(0.0) // 1 ^ 1 = 0 }; Network network = new Network(new int[]{2, 3, 1}); // создаём сеть с двумя входами, тремя нейронами в скрытом слое и одним выходом Luego comenzamos a entrenar con los siguientes parámetros: tasa de aprendizaje – 0.5, número de épocas – 100000, valor de error – 1e-7:
network.Train(X, Y, 0.5, 1e-7, 100000); // запускаем обучение сети Después del entrenamiento, veamos los resultados realizando un pase directo para todos los elementos:
for (int i = 0; i Fuente de grabación: lastici.ru