En termes simples sur le complexe: que sont les réseaux de neurones? Ecrire un réseau de neurones feedforward à partir de zéro.

Qu’est-ce qu’un réseau neuronal?
Comme vous le savez, notre cerveau est une chose complexe. La coordination de son travail se fait par le biais de neurones – des cellules nerveuses avec des branches partant d’eux. Entrelacés les uns avec les autres, les neurones forment un réseau neuronal – un mécanisme complexe qui détermine toute la diversité de la psyché humaine. C’est la racine de notre conscience de soi, le sentiment de nous en tant qu’individus, guidés par nos désirs intérieurs et nos aspirations.
Si un dysfonctionnement se produit dans le travail des neurones, la personne change au-delà de la reconnaissance. Selon la gravité de la blessure, les changements vont de légers signes de comportement déviant à l’arrêt du fonctionnement normal du corps. Les lésions cérébrales sont souvent mortelles.
Mais aujourd’hui, nous ne parlerons pas de biologie, car non seulement le système de notre cerveau est appelé réseaux de neurones, mais aussi un programme informatique complexe avec des principes de fonctionnement similaires. Comme la matière grise, elle est fractale, c’est-à-dire qu’elle se compose de nombreux programmes plus simples qui forment une sorte de symbiose.
Tout en fonctionnant, le réseau neuronal apprend, acquiert de l’expérience et devient plus parfait. Ainsi, nous avons affaire à un véritable organisme numérique, qui devrait un jour surpasser son créateur.
Comment les réseaux de neurones sont apparus
L’émergence du concept de réseaux de neurones artificiels remonte aux années 40 du siècle précédent. En particulier, il est associé aux scientifiques McCulloch et Pitts, qui ont tenté de simuler les processus du cerveau. Ils ont également proposé l’idée de créer un système d’auto-apprentissage conçu pour effectuer diverses opérations logiques. Le problème était que les technologies de l’époque étaient loin de celles d’aujourd’hui et que les inventeurs n’avaient pas pleinement réalisé leurs idées.
(Warren McCulloch et Walter Pitts)
Leur travail a été poursuivi par le physiologiste canadien Donald Hebb et, en 1949, le premier algorithme de calcul ANN a été présenté au monde. Pendant les 10 années suivantes, il a servi de base au développement d’autres scientifiques, jusqu’à ce que, finalement, en 1958, Frank Rosenblatt crée le parceptron, une technologie qui imite le travail de notre cerveau. Pour l’époque, cette nouveauté était incroyable. Des scientifiques soviétiques et américains se sont joints aux travaux, qui ont également apporté une contribution considérable à la recherche.
À la fin du XXe siècle et au début du XXIe siècle, la technologie a fait un bond en avant, ce qui a été une bonne incitation à une activité scientifique plus intensive, et en 2007, l’informaticien Jeffrey Hinton a proposé un algorithme d’apprentissage en profondeur pour les réseaux de neurones, qui est maintenant largement utilisé. dans les voitures autonomes.

(Geoffrey Hinton)
Un peu d’histoire
Pour la première fois, le concept de réseaux neuronaux artificiels (RNA) est apparu en essayant de simuler les processus du cerveau. La première avancée majeure dans ce domaine peut être considérée comme la création du modèle de réseau neuronal McCulloch-Pitts en 1943. Les scientifiques ont d’abord développé un modèle de neurone artificiel. Ils ont également proposé la construction d’un réseau de ces éléments pour effectuer des opérations logiques. Mais surtout, les scientifiques ont prouvé qu’un tel réseau est capable d’apprendre.

La prochaine étape importante a été le développement par Donald Hebb du premier algorithme de calcul ANN en 1949, qui est devenu fondamental pour les décennies suivantes. En 1958, Frank Rosenblatt a développé le parceptron, un système qui imite les processus du cerveau. À une époque, la technologie n’avait pas d’analogues et est toujours fondamentale dans les réseaux de neurones. En 1986, presque simultanément, indépendamment les uns des autres, les scientifiques américains et soviétiques ont considérablement amélioré la méthode fondamentale d’enseignement du perceptron multicouche. En 2007, les réseaux de neurones ont connu une renaissance. Informaticien britannique Jeffrey Hinton a d’abord développé un algorithme d’apprentissage en profondeur pour les réseaux de neurones multicouches, qui est maintenant, par exemple, utilisé pour faire fonctionner des véhicules sans pilote.
En bref sur l’essentiel
Au sens général du terme, les réseaux de neurones sont des modèles mathématiques qui fonctionnent sur le principe des réseaux de cellules nerveuses dans un organisme animal. Les ANN peuvent être implémentés dans des solutions programmables et matérielles. Pour faciliter la perception, un neurone peut être imaginé comme une sorte de cellule, qui a de nombreux trous d’entrée et une sortie. Le nombre de signaux entrants formés dans le signal sortant détermine l’algorithme de calcul. Les valeurs effectives sont transmises à chaque entrée neuronale, qui sont ensuite propagées le long des connexions interneuronales (synopsis). Les synapses ont un paramètre – le poids, en raison duquel les informations d’entrée changent lors du passage d’un neurone à un autre. La manière la plus simple d’imaginer le fonctionnement des réseaux de neurones peut être représentée par l’exemple du mélange de couleurs. Les neurones bleus, verts et rouges ont des poids différents.
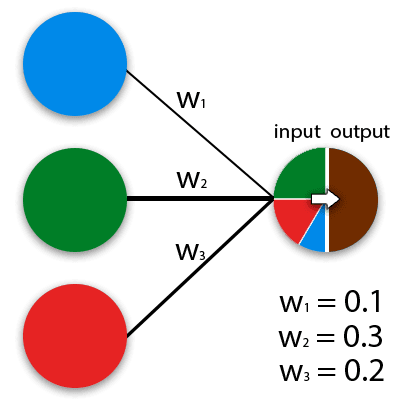
Le réseau neuronal lui-même est un système de nombreux neurones (processeurs). Séparément, ces processeurs sont assez simples (beaucoup plus simples qu’un processeur d’ordinateur personnel), mais lorsqu’ils sont connectés à un grand système, les neurones sont capables d’effectuer des tâches très complexes.
Selon le domaine d’application, un réseau de neurones peut être interprété de différentes manières.Par exemple, du point de vue de l’apprentissage automatique, un ANN est une méthode de reconnaissance de formes. D’un point de vue mathématique, il s’agit d’un problème à paramètres multiples. Du point de vue de la cybernétique, c’est un modèle de contrôle adaptatif de la robotique. Pour l’intelligence artificielle, ANN est un composant fondamental de la modélisation de l’intelligence naturelle à l’aide d’algorithmes de calcul.
Le principal avantage des réseaux de neurones par rapport aux algorithmes de calcul conventionnels est leur capacité à apprendre. Au sens général du terme, l’apprentissage consiste à trouver les coefficients de couplage corrects entre neurones, ainsi qu’à généraliser des données et à identifier des relations complexes entre les signaux d’entrée et de sortie. En fait, un apprentissage réussi d’un réseau neuronal signifie que le système sera en mesure d’identifier le résultat correct sur la base de données non présentes dans l’ensemble d’apprentissage.
Application des réseaux de neurones
Le champ d’application des réseaux de neurones est incroyablement large et n’est limité que par notre imagination. Énumérons quelques-uns d’entre eux:
- Systèmes de contrôle automatique du transport. Pilotes automatiques.
- L’Internet. Assistants vocaux, navigateurs intelligents, programmes de traduction.
- Économie et affaires. Prévision des taux de change, programmes comptables modernes, robots de trading, programmes d’évaluation des risques, gestion des machines de production, contrôle qualité, etc.
- Médicament. Méthodes modernes de diagnostic, d’analyse de l’efficacité du traitement, de traitement des images médicales.
- Robotique. Planification d’itinéraire, reconnaissance vocale et gestuelle.
- Sécurité. Gestion des systèmes de vidéosurveillance et des alarmes.
- Jeux informatiques et divertissement. Bots intelligents, programmes analytiques pour les échecs et autres jeux.
- De l’art. Création de peintures, livres et autres objets culturels.

La situation d’aujourd’hui
Et aussi prometteuse que soit cette technologie, les ANN sont encore très loin des capacités du cerveau et de la pensée humains. Néanmoins, les réseaux de neurones sont déjà utilisés dans de nombreux domaines de l’activité humaine. Jusqu’à présent, ils ne sont pas en mesure de prendre des décisions hautement intellectuelles, mais ils sont capables de remplacer une personne là où elle était auparavant nécessaire. Parmi les nombreux domaines d’application ANN, on peut noter: la création de systèmes d’auto-apprentissage des processus de production, de véhicules sans pilote, de systèmes de reconnaissance d’image, de systèmes de sécurité intelligents, de robotique, de systèmes de surveillance de la qualité, d’interfaces d’interaction vocale, de systèmes d’analyse et bien plus encore. Cette utilisation généralisée des réseaux de neurones est, entre autres, due à l’émergence de diverses manières d’accélérer l’apprentissage de l’ANN.
Aujourd’hui, le marché des réseaux de neurones est énorme – il représente des milliards et des milliards de dollars. Comme le montre la pratique, la plupart des technologies des réseaux de neurones dans le monde diffèrent peu les unes des autres. Cependant, l’utilisation de réseaux de neurones est une entreprise très coûteuse qui, dans la plupart des cas, ne peut être financée que par les grandes entreprises. Pour le développement, la formation et le test des réseaux de neurones, une grande puissance de calcul est nécessaire, il est évident que les grands acteurs du marché informatique en ont assez. La division DeepMind de Google, la division Microsoft Research, IBM, Facebook et Baidu figurent parmi les principales entreprises à la pointe du développement dans ce domaine.
Bien sûr, tout cela est bien: les réseaux de neurones se développent, le marché se développe, mais jusqu’à présent, la tâche principale n’a pas été résolue. L’humanité n’a pas réussi à créer une technologie dont les capacités sont même proches du cerveau humain. Jetons un coup d’œil aux principales différences entre le cerveau humain et les réseaux de neurones artificiels.
Pourquoi les réseaux de neurones sont-ils encore loin du cerveau humain?
La différence la plus importante, qui change fondamentalement le principe et l’efficacité du système, est la transmission différente du signal dans les réseaux de neurones artificiels et dans le réseau biologique des neurones. Le fait est que dans l’ANN, les neurones transmettent des valeurs qui sont des valeurs réelles, c’est-à-dire des nombres. Dans le cerveau humain, des impulsions d’amplitude fixe sont transmises et ces impulsions sont presque instantanées. Par conséquent, le réseau humain de neurones présente un certain nombre d’avantages.
Premièrement, les lignes de communication dans le cerveau sont beaucoup plus efficaces et économiques que dans les ANN. Deuxièmement, le circuit d’impulsions assure la simplicité de la mise en œuvre de la technologie: il suffit d’utiliser des circuits analogiques au lieu de mécanismes de calcul complexes. En fin de compte, les réseaux d’impulsions sont protégés des interférences acoustiques. Les nombres effectifs sont sujets au bruit, ce qui augmente la probabilité d’erreurs.
Perspectives des réseaux de neurones
Le mouvement luddite a commencé au début du 19e siècle. Ce mot était utilisé pour décrire les personnes participant à des manifestations contre l’urbanisation. Avec l’industrialisation de la société, lorsque les machines-outils ont commencé à remplacer progressivement les travailleurs, de nombreuses personnes se sont retrouvées sans travail et étaient extrêmement insatisfaites de leur situation. Imaginez le choc qu’ils auraient vécu s’ils avaient appris que dans deux cents ans, les machines seraient capables de parler et même de se déplacer de manière autonome!
Pendant ce temps, ces temps sont venus, et aujourd’hui, il y a aussi des rétrogrades qui craignent que la robotique et le développement de la technologie en général puissent jouer une blague cruelle avec les gens. Après tout, si les machines sont déjà capables d’exécuter autant de tâches aujourd’hui, elles occuperont à l’avenir tous les emplois, rendant les gens inutiles. Et cette position n’est confirmée que par les appréciations d’experts qui prédisent de temps à autre la disparition imminente d’une profession particulière.
Cette position a le droit d’exister, mais elle n’est pas tout à fait correcte, car avec le temps, non seulement les anciennes professions disparaissent, mais de nouvelles apparaissent également. Oui, il y a un ordre de grandeur moins de bergers et de chasseurs qu’avant, mais des programmeurs et des spécialistes du marketing sont apparus. Aux tournants de l’histoire, l’économie se réoriente, éliminant les inutiles et dotant généreusement ceux qui sont en demande.
L’influence croissante des réseaux de neurones artificiels est évidente, et il est probable que bientôt ils seront littéralement partout, mais en avoir peur signifie rejeter la nature humaine elle-même, qui consiste dans le désir de découverte et d’accomplissement.
Création de blocs neuronaux
Tout d’abord, vous devez décider quels sont les composants de base d’un réseau neuronal – les neurones -. Le neurone prend les données d’entrée, effectue certaines opérations mathématiques avec lui, puis sort le résultat. Un neurone avec deux entrées ressemble à ceci:
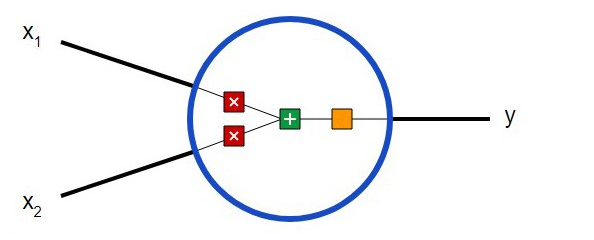
Trois choses se passent ici. Tout d’abord, chaque entrée est multipliée par son poids (indiqué en rouge sur le diagramme ):
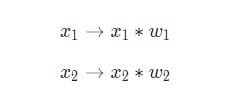
Ensuite, toutes les entrées pondérées sont additionnées avec le décalage b(indiqué en vert dans le diagramme ):
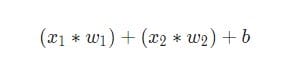
Enfin, le montant est transféré via la fonction d’activation (marquée en jaune sur le schéma ):

La fonction d’activation est utilisée pour connecter des entrées indépendantes à une sortie qui a une forme simple et prévisible. En règle générale, la fonction sigmoïde est considérée comme la fonction d’activation utilisée :
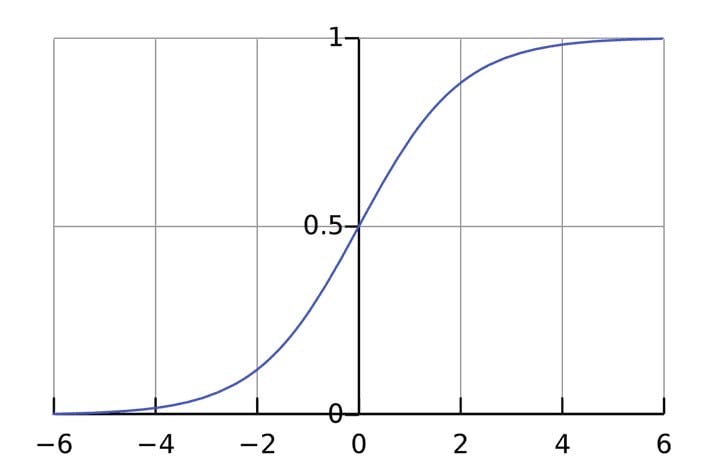
La fonction sigmoïde ne produit que des nombres dans une plage (0, 1). Vous pouvez le considérer comme une compression de (−∞, +∞)à (0, 1). De grands nombres négatifs deviennent ~0, et de grands nombres positifs deviennent ~1.
Un exemple simple de travail avec des neurones en Python
Supposons que nous ayons un neurone avec deux entrées qui utilise une fonction d’ activation sigmoïde et qui a les paramètres suivants:
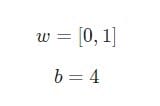
w = [0,1]Est juste une manière d’écrire w1 = 0, w2 = 1sous forme vectorielle. Attribuons une entrée avec une valeur au neurone x = [2, 3]. Pour une représentation plus compacte, le produit scalaire sera utilisé .
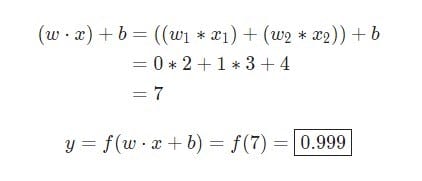
Étant donné que l’entrée était x = [2, 3], la sortie sera égale 0.999. C’est tout. Ce processus de transmission des données d’entrée pour recevoir la sortie est appelé anticipation.
Construire un neurone à partir de zéro en Python
Commençons par implémenter le neurone. Cela nécessitera l’utilisation de NumPy. Il s’agit d’une puissante bibliothèque de calcul Python qui utilise des opérations mathématiques:
|
une 2 3 quatre cinq 6 7 huit neuf dix Onze 12 13 Quatorze quinze seize 17 dix-huit dix-neuf vingt 21 22 23 24 25 26 27 |
importer numpy en tant que np def sigmoïde ( x ) : # Notre fonction d’activation: f (x) = 1 / (1 + e ^ (- x)) retourne 1 / ( 1 + np . exp ( – x ) ) classe Neuron : def __init__ ( soi , poids , biais ) : soi . poids = poids soi . biais = biais def feedforward ( soi , entrées ) : # Entrer les données de poids, ajouter un décalage # et utilisation ultérieure de la fonction d’activation total = np . point ( auto . poids , entrées ) + self . biais retour sigmoïde ( total ) poids = np . tableau ( [ 0 , 1 ] ) # w1 = 0, w2 = 1 biais = 4 # b = 4 n = Neuron ( poids , biais ) x = np . tableau ( [ 2 , 3 ] ) # x1 = 2, x2 = 3 impression ( n . avance ( x ) ) # 0.9990889488055994 |
Reconnaissez-vous les chiffres? C’est le même exemple évoqué précédemment. La réponse reçue cette fois est également égale 0.999.
Un exemple de collecte de neurones dans un réseau de neurones
Un réseau de neurones est essentiellement un groupe de neurones interconnectés. Un simple réseau de neurones ressemble à ceci:
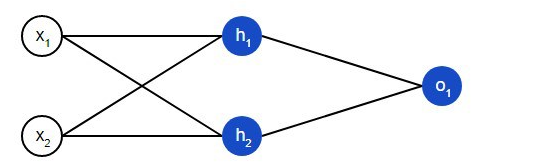
Sur la couche d’introduction du réseau, il y a deux entrées – x1et x2. Il y a deux neutrons sur la couche cachée – h1et h2. Il y a un neurone sur la couche de sortie – о1. Notez que les entrées pour о1sont des résultats de sortie h1et h2. C’est ainsi que se construit le réseau neuronal.
Un calque masqué est tout calque entre le calque d’entrée et le calque de sortie, qui sont respectivement les premier et dernier calques. Il peut y avoir plusieurs couches cachées.
Formation sur les réseaux neuronaux
Sortie ŷ d’un simple réseau de neurones à deux couches:
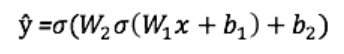
Dans l’équation ci-dessus, les poids W et les biais b sont les seules variables qui affectent la sortie ŷ.
Naturellement, les valeurs correctes des pondérations et des biais déterminent la précision des prédictions. Le processus d’ajustement des poids et des biais à partir des données d’entrée est connu sous le nom de formation de réseau neuronal.
Chaque itération du processus de formation comprend les étapes suivantes
- calcul de la sortie prédite ŷ appelée propagation directe
- mise à jour des poids et biais appelés rétropropagation
Le graphique séquentiel ci-dessous illustre le processus:

Distribution directe
Comme nous l’avons vu dans le graphique ci-dessus, la propagation directe n’est qu’un simple calcul, et pour un réseau neuronal de base à 2 couches, la sortie du réseau neuronal est donnée par:
Ajoutons du feedforward à notre code Python pour ce faire. Notez que pour simplifier, nous avons supposé que les décalages sont de 0.
Cependant, nous avons besoin d’un moyen d’évaluer la «qualité» de nos prévisions, c’est-à-dire dans quelle mesure nos prévisions sont). La fonction de perte nous permet de faire exactement cela.
Fonction de perte
Il existe de nombreuses fonctions de perte disponibles, et la nature de notre problème devrait dicter notre choix de fonction de perte. Dans cet article, nous utiliserons la somme des carrés des erreurs comme fonction de perte.

La somme des erreurs au carré est la moyenne de la différence entre chaque valeur prédite et la valeur réelle.
Le but de la formation est de trouver un ensemble de poids et de biais qui minimise la fonction de perte.
Propagation arrière
Maintenant que nous avons mesuré notre erreur de prévision (pertes), nous devons trouver un moyen de propager l’erreur et de mettre à jour nos pondérations et nos biais.
Pour trouver la quantité appropriée à corriger pour les pondérations et les biais, nous devons connaître la dérivée de la fonction de perte par rapport aux pondérations et aux biais.
Rappelons de l’analyse que la dérivée d’une fonction est la tangente de la pente de la fonction.
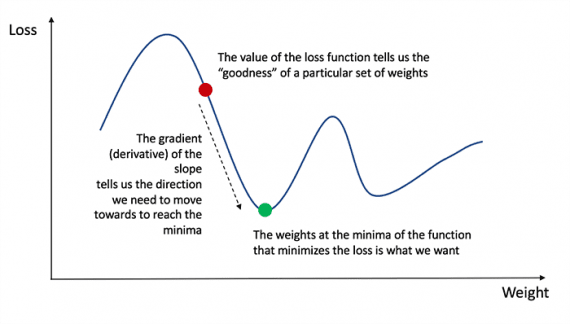
Si nous avons une dérivée, nous pouvons simplement mettre à jour les poids et les biais en les augmentant / en les diminuant (voir le diagramme ci-dessus). C’est ce qu’on appelle la descente de gradient.
Cependant, nous ne pouvons pas calculer directement la dérivée de la fonction de perte par rapport aux poids et biais, puisque l’équation de la fonction de perte ne contient pas de poids et de biais. Par conséquent, nous avons besoin d’une règle de chaîne pour faciliter le calcul.
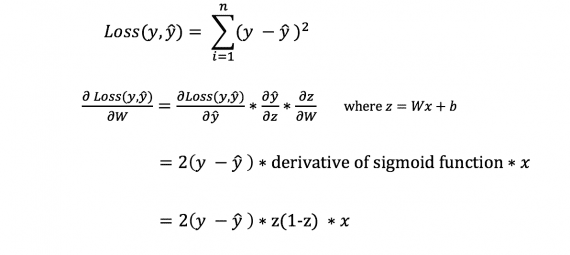
Fuh! C’était encombrant, mais cela nous permettait d’obtenir ce dont nous avions besoin – la dérivée (pente) de la fonction de perte par rapport aux poids. Nous pouvons maintenant ajuster les poids en conséquence.
Ajoutons la fonction de rétropropagation à notre code Python:
Dérivées partielles
Des dérivées partielles peuvent être calculées, de sorte que l’on sait quelle a été la contribution à l’erreur pour chaque poids. Le besoin de produits dérivés est évident. Imaginez un réseau de neurones essayant de trouver la vitesse optimale pour un véhicule autonome. Si la voiture détecte qu’elle va plus vite ou plus lentement que la vitesse requise, le réseau neuronal changera la vitesse, accélérant ou ralentissant la voiture. Qu’est-ce que l’accélération / la décélération dans ce cas? Dérivés de vitesse.
Regardons le besoin de dérivées partielles à l’aide d’un exemple.
Supposons qu’on demande aux enfants de lancer une fléchette sur une cible, en visant le centre. Voici les résultats:

Maintenant, si nous trouvons une erreur générale et la soustrayons simplement de tous les poids, nous résumerons les erreurs commises par chacun. Donc, disons que l’enfant a frappé trop bas, mais nous demandons à tous les enfants de s’efforcer d’atteindre la cible, cela conduira à l’image suivante:
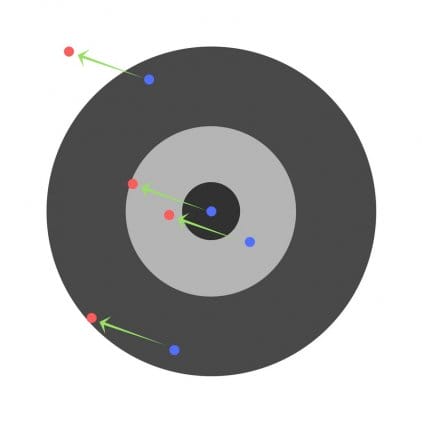
L’erreur de plusieurs enfants peut diminuer, mais l’erreur totale continue d’augmenter.
Après avoir trouvé les dérivées partielles, nous découvrons les erreurs correspondant à chaque poids séparément. Si vous corrigez sélectivement les poids, vous pouvez obtenir ce qui suit:
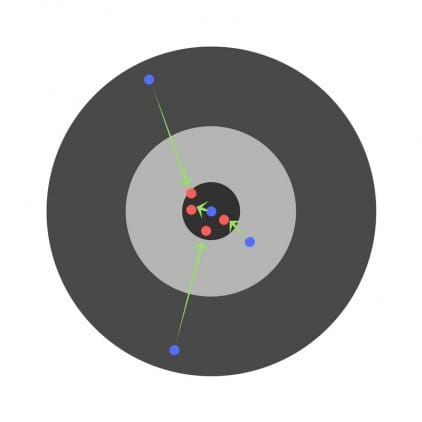
Hyperparamètres
Un réseau neuronal est utilisé pour automatiser la sélection des fonctionnalités, mais certains paramètres sont configurés manuellement.
Taux d’apprentissage
Le taux d’apprentissage est un hyperparamètre très important. Si le taux d’apprentissage est trop faible, même après avoir entraîné le réseau neuronal pendant une longue période, les résultats seront loin d’être optimaux. Les résultats ressembleront à ceci:
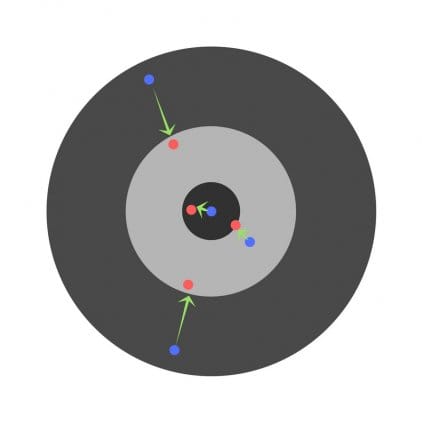
En revanche, si le taux d’apprentissage est trop élevé, le réseau répondra très rapidement. Le résultat est le suivant:

Réseaux de neurones profonds
L’apprentissage en profondeur est une classe d’algorithmes d’apprentissage automatique qui apprennent à comprendre les données plus profondément (de manière plus abstraite). Les algorithmes populaires pour les réseaux de neurones d’apprentissage en profondeur sont présentés dans le diagramme ci-dessous.
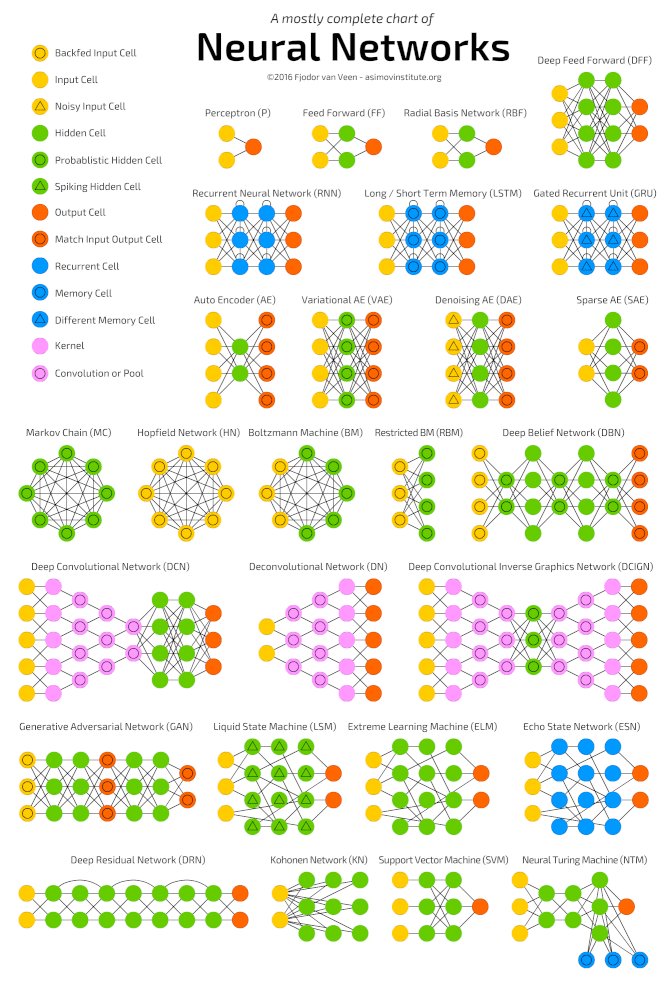
Algorithmes de réseau de neurones populaires (http://www.asimovinstitute.org/neural-network-zoo )
Plus formellement dans le deep learning:
- Une cascade (pipeline, sous forme de flux transmis séquentiellement) d’une pluralité de couches de traitement (non linéaires) est utilisée pour extraire et transformer des caractéristiques;
- Basé sur l’étude des caractéristiques (présentation des informations) dans les données sans apprentissage supervisé. Les fonctions de niveau supérieur (qui sont dans les dernières couches) sont obtenues à partir des fonctions de niveau inférieur (qui sont dans les couches des couches initiales);
- Explore les vues en couches qui correspondent à différents niveaux d’abstraction; les niveaux forment une hiérarchie de présentation.
Former le réseau neuronal à l’aide des fonctions XOR
Pourquoi la fonction XOR est-elle si intéressante? Simplement parce qu’il ne peut pas être obtenu par un neurone: 0 ^ 0 = 0, 0 ^ 1 = 1, 1 ^ 0 = 1, 1 ^ 1 = 0. Cependant, il est facilement obtenu en augmentant le nombre de neurones. Nous allons essayer de former un réseau avec 3 neurones dans la couche cachée et 1 sortie (puisque nous n’avons qu’une seule sortie). Pour ce faire, nous devons créer un tableau de vecteurs X et Y avec des données d’entraînement et le réseau neuronal lui-même:
// массив входных обучающих векторов Vector[] X = { new Vector(0, 0), new Vector(0, 1), new Vector(1, 0), new Vector(1, 1) }; // массив выходных обучающих векторов Vector[] Y = { new Vector(0.0), // 0 ^ 0 = 0 new Vector(1.0), // 0 ^ 1 = 1 new Vector(1.0), // 1 ^ 0 = 1 new Vector(0.0) // 1 ^ 1 = 0 }; Network network = new Network(new int[]{2, 3, 1}); // создаём сеть с двумя входами, тремя нейронами в скрытом слое и одним выходом Ensuite, nous commençons l’entraînement avec les paramètres suivants: taux d’apprentissage – 0,5, nombre d’époques – 100000, valeur d’erreur – 1e-7:
network.Train(X, Y, 0.5, 1e-7, 100000); // запускаем обучение сети Après l’entraînement, regardons les résultats en effectuant un passage direct pour tous les éléments:
for (int i = 0; i Source d’enregistrement: lastici.ru