Простими словами про складне: що таке нейронні мережі? Пишемо нейросеть прямого поширення з нуля.

Зміст
Що таке нейронна мережа?
Як відомо, наш мозок – штука складна. Координація його роботи відбувається за допомогою нейронів – нервових клітин відходять від них відростками. Переплітаючись між собою, нейрони утворюють нейронну мережу – заплутаний механізм, що визначає все різноманіття людської психіки. Це корінь нашого самосвідомості, відчуття нас як індивідів, які керуються своїми внутрішніми бажаннями і прагненнями.
Якщо в роботі нейронів відбувається якийсь збій, людина змінюється до невпізнання. Залежно від тяжкості ушкодження зміни варіюються – від легких ознак девіантної поведінки до припинення нормального функціонування організму. Найчастіше пошкодження мозку призводять до летального результату.
Але говорити ми сьогодні будемо нема про біології, адже нейронними мережами називається не тільки система нашого мозку, але і складна комп'ютерна програма зі схожими принципами роботи. Як і сіра речовина, вона фрактальна, тобто складається з безлічі більш простих програм, що утворюють свого роду симбіоз.
Функціонуючи, нейросеть вчиться, накопичує досвід і стає досконалішим. Таким чином, ми маємо справу зі справжнім цифровим організмом, якому пророкують одного разу перевершити свого творця.
Як з'явилися нейронні мережі
Поява концепції штучних нейромереж відносять до 40-х років попереднього століття. Зокрема, воно пов'язане з вченими Маккаллок і Питтсом, які намагалися змоделювати процеси головного мозку. Ними ж була запропонована ідея створення самонавчальної системи, покликаної виконувати різні логічні операції. Проблема полягала в тому, що технології того часу були далекі від сьогоднішніх, і в повній мірі реалізувати свої задумки винахідникам не вдалося.
(Уоррен Маккаллок і Уолтер Піттс)
Їх справу продовжив канадський фізіолог Дональд Хебб, і в 1949 році світу був представлений перший алгоритм обчислень ІНС. У наступні 10 років він служив базою для розробок інших вчених, поки, нарешті, в 1958 Френк Розенблат не створив парцептрон – технологію, яка імітує роботу нашого мозку. Для свого часу ця новинка була неймовірною. До роботи підключилися радянські і американські вчені, які також внесли чималу лепту в дослідження.
В кінці XX – початку XXI століть технології зробили різкий стрибок, що послужило хорошим стимулом для більш інтенсивної наукової діяльності, і в 2007-му інформатик Джеффрі Хінтон придумав алгоритм глибокого навчання нейронних мереж, який зараз широко використовується в безпілотних автомобілях.

(Джеффрі Хінтон)
Трохи історії
Вперше поняття штучних нейронних мереж (ІНС) виникло при спробі змоделювати процеси головного мозку. Першим серйозним проривом в цій сфері можна вважати створення моделі нейронних мереж Маккаллок-Питтса в 1943 році. Вченими вперше була розроблена модель штучного нейрона. Ними також була запропонована конструкція мережі з цих елементів для виконання логічних операцій. Але найголовніше, вченими було доведено, що подібна мережа здатна навчатися.

Наступним важливим кроком стала розробка Дональдом Хеббом першого алгоритму обчислення ІНС в 1949 році, який став основоположному на кілька наступних десятиліть. У 1958 році Френк Розенблат був розроблений парцептрон – система, що імітує процеси головного мозку. Свого часу технологія не мала аналогів і до сих пір є неодмінною умовою збереження нейронних мережах. У 1986 році практично одночасно, незалежно один від одного американськими і радянськими вченими було суттєво доопрацьовано основоположний метод навчання багатошарового перцептрона. У 2007 році нейронні мережі перенесли друге народження. Британський інформатик Джеффрі Хінтон вперше розробив алгоритм глибокого навчання багатошарових нейронних мереж, який зараз, наприклад, використовується для роботи безпілотних автомобілів.
Коротко про головне
У загальному сенсі слова, нейронні мережі – це математичні моделі, що працюють за принципом мереж нервових клітин тваринного організму. ІНС можуть бути реалізовані як в програмовані, так і в апаратні рішення. Для простоти сприйняття нейрон можна уявити, як якусь комірку, у якій є безліч вхідних отворів і один вихідний. Яким чином численні вхідні сигнали формуються в виходить, як раз і визначає алгоритм обчислення. На кожен вхід нейрона подаються дієві значення, які потім поширюються по міжнейронних зв'язків (синопсис). У синапсів є один параметр – вага, завдяки якому вхідна інформація змінюється при переході від одного нейрона до іншого. Найлегше принцип роботи нейромереж можна уявити на прикладі змішування кольорів. Синій, зелений і червоний нейрон мають різні ваги.
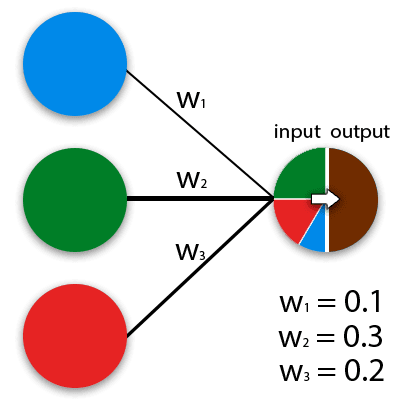
Сама нейросеть являє собою систему з безлічі таких нейронів (процесорів). Окремо ці процесори досить прості (набагато простіше, ніж процесор персонального комп'ютера), але будучи з'єднаними в більшу систему нейрони здатні виконувати дуже складні завдання.
Залежно від області застосування нейросеть можна трактувати по-різному, наприклад, з точки зору машинного навчання ІНС є метод розпізнавання образів. З математичної точки зору – це багатопараметрична завдання. З точки зору кібернетики – модель адаптивного управління робототехнікою. Для штучного інтелекту ІНС – це основне становить для моделювання природного інтелекту за допомогою обчислювальних алгоритмів.
Основною перевагою нейромереж над звичайними алгоритмами обчислення є їх можливість навчання. У загальному сенсі слова навчання полягає в знаходженні вірних коефіцієнтів зв'язку між нейронами, а також в узагальненні даних і виявленні складних залежностей між вхідними та вихідними сигналами. Фактично, вдале навчання нейромережі означає, що система буде здатна виявити вірний результат на підставі даних, відсутніх в навчальній вибірці.
Застосування нейронних мереж
Спектр застосування нейромереж неймовірно широкий і обмежений лише нашою фантазією. Перерахуємо деякі з них:
- Автоматичні системи управління транспортом. Автопілот.
- Інтернет. Голосові помічники, розумні браузери, програми-перекладачі.
- Економіка і бізнес. Прогнозування курсів валют, сучасні бухгалтерські програми, торгові роботи, програми оцінки ризиків, управління виробничими верстатами, контроль якості і т.д.
- Медицина. Сучасні методи постановки діагнозу, аналіз ефективності лікування, обробка медичних зображень.
- Робототехніка. Прокладання маршрутів руху, розпізнавання мови і жестів.
- Безпека. Управління системами відеоспостереження і сигналізацією.
- Комп'ютерні ігри і сфера розваг. «Розумні» боти, аналітичні програми для шахів і інших ігор.
- Мистецтво. Створення картин, книг та інших культурних артефактів.

сьогоднішнє становище
І якою б багатообіцяючою не була б ця технологія, поки що ІНС ще дуже далекі від можливостей людського мозку і мислення. Проте, вже зараз нейромережі застосовуються в багатьох сферах діяльності людини. Поки що вони не здатні приймати високоінтелектуальні рішення, але в змозі замінити людину там, де раніше він був необхідний. Серед численних областей застосування ІНС можна відзначити: створення самообучающихся систем виробничих процесів, безпілотні транспортні засоби, системи розпізнавання зображень, інтелектуальні охоронні системи, робототехніка, системи моніторингу якості, голосові інтерфейси взаємодії, системи аналітики та багато іншого. Таке широке поширення нейромереж крім іншого обумовлено появою різних способів прискорення навчання ІНС.
На сьогоднішній день ринок нейронних мереж величезний – це мільярди і мільярди доларів. Як показує практика, більшість технологій нейромереж по всьому світу мало відрізняються один від одного. Однак застосування нейромереж – це дуже витратне заняття, яке в більшості випадків можуть дозволити собі лише великі компанії. Для розробки, навчання і тестування нейронних мереж потрібні великі обчислювальні потужності, очевидно, що цього в достатку є у великих гравців на ринку ІТ. Серед основних компаній, провідних розробки в цій області можна відзначити підрозділ Google DeepMind, підрозділ Microsoft Research, компанії IBM, Facebook і Baidu.
Звичайно, все це добре: нейромережі розвиваються, ринок зростає, але поки що головне завдання так і не вирішена. Людству не вдалося створити технологію, хоча б наближену за можливостями до людського мозку. Давайте розглянемо основні відмінності між людським мозком і штучними нейросетями.
Чому нейромережі ще далекі до людського мозку?
Найголовнішою відмінністю, яке докорінно змінює принцип і ефективність роботи системи – це різна передача сигналів в штучних нейронних мережах і в біологічній мережі нейронів. Справа в тому, що в ІНС нейрони передають значення, які є дійсними значеннями, тобто числами. У людському мозку здійснюється передача імпульсів з фіксованою амплітудою, причому ці імпульси практично миттєві. Звідси випливає цілий ряд переваг людської мережі нейронів.
По-перше, лінії зв'язку в мозку набагато ефективніше і економніше, ніж в ІНС. По-друге, імпульсна схема забезпечує простоту реалізації технології: досить використання аналогових схем замість складних обчислювальних механізмів. В кінцевому рахунку, імпульсні мережі захищені від звукових перешкод. Дієві числа схильні до впливу шумів, в результаті чого підвищується ймовірність виникнення помилки.
перспективи нейромереж
Рух луддитів зародилося на початку XIX століття. Цим словом називали людей, що беруть участь в акціях протесту проти урбанізації. З індустріалізацією суспільства, коли верстати почали потроху замінювати робочі руки, багато людей залишилися без роботи і були вкрай незадоволені своїм становищем. Тільки уявіть, який шок б вони відчули, дізнавшись, що через пару сотень років верстати зможуть розмовляти і навіть самостійно пересуватися!
Тим часом ці часи настали, і сьогодні теж є ретрогради, які побоюються, що робототехніка і взагалі розвиток технологій може зіграти з людьми жорстокий жарт. Адже якщо вже сьогодні машини здатні виконувати так багато завдань, в майбутньому вони займуть всі робочі місця, зробивши людей непотрібними. І ця позиція тільки підтверджується оцінками експертів, які раз у раз прогнозують швидке зникнення тієї чи іншої професії.
Така позиція має право на життя, але вона не зовсім вірна, тому що з плином часу не тільки зникають старі професії, а й з'являються нові. Так, пастухів і мисливців зараз на порядок менше, ніж раніше, але зате з'явилися програмісти і маркетологи. На поворотних етапах історії економіка переорієнтовується, відсіваючи непотрібне і щедро обдаровуючи тих, хто затребуваний.
Зростаючий вплив штучних нейронних мереж очевидно, і цілком ймовірно, що незабаром вони будуть буквально всюди, але боятися цього – значить відкидати саму людську природу, яка полягає в тязі до відкриттів і звершень.
Створення нейронних блоків
Для початку необхідно визначитися з тим, що з себе представляють базові компоненти нейронної мережі – нейрони. Нейрон приймає вступні дані, виконує з ними певні математичні операції, а потім виводить результат. Нейрон з двома вхідними даними виглядає наступним чином:
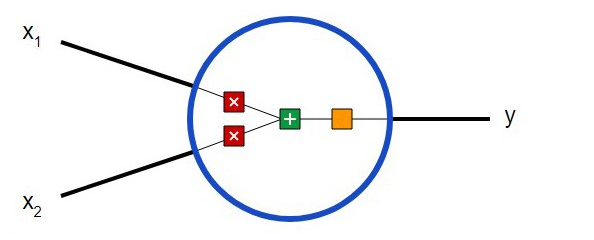
Тут відбуваються три речі. По-перше, кожен вхід множиться на вагу (на схемі позначений червоним ):
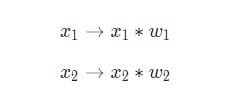
Потім все зважені входи складаються разом зі зміщенням b(на схемі позначений зеленим ):
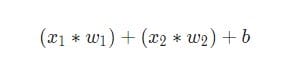
Нарешті, сума передається через функцію активації (на схемі позначена жовтим ):

Функція активації використовується для підключення незв'язаних вхідних даних з висновком, у якого проста і передбачувана форма. Як правило, в якості використовуваної функцією активації береться функція сигмоїда :
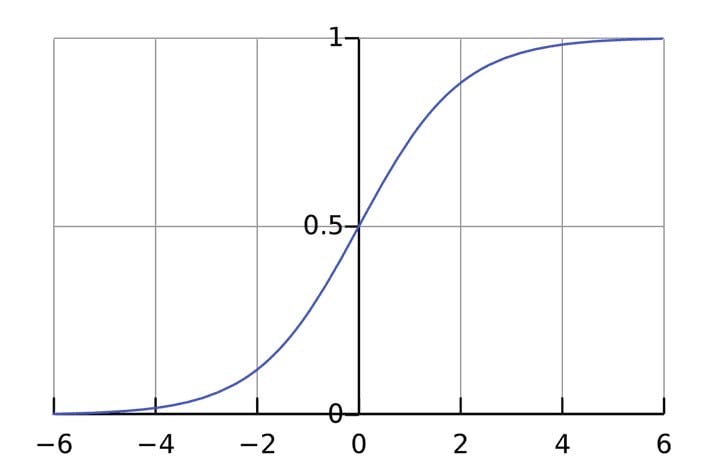
Функція сигмоїда виводить тільки числа в діапазоні (0, 1). Ви можете сприймати це як компресію від (−∞, +∞)до (0, 1). Великі негативні числа стають ~0, а великі позитивні числа стають ~1.
Простий приклад роботи з нейронами в Python
Припустимо, у нас є нейрон з двома входами, який використовує функцію активації сигмоїда і має наступні параметри:
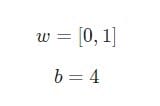
w = [0,1]– це просто один із способів написання w1 = 0, w2 = 1в векторній формі. Дамо нейрона вхід зі значенням x = [2, 3]. Для більш компактного представлення буде використано скалярний твір.
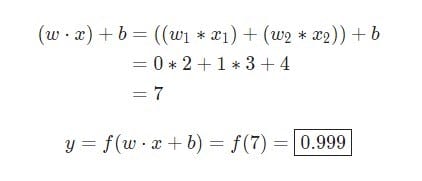
З урахуванням, що вхід був x = [2, 3], висновок буде дорівнює 0.999. От і все. Такий процес передачі вхідних даних для отримання висновку називається прямим поширенням, або feedforward.
Створення нейрона з нуля в Python
Приступимо до імплементації нейрона. Для цього буде потрібно використовувати NumPy. Це потужна обчислювальна бібліотека Python, яка задіює математичні операції:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
імпортувати numpy як np def sigmoid ( x ) : # Наша функція активації: f (x) = 1 / (1 + e ^ (- x)) повернути 1 / ( 1 + np . exp ( – x ) ) клас Нейрон : def __init__ ( self , weights , bias ) : себе . ваги = ваги себе . упередженість = упередженість def forwardforward ( self , inputs ) : # Вступні дані про вагу, додавання зсуву # І подальше використання функції активації загальна = np . крапка ( само . ваги , вводи ) + само . упередженість повернути сигмовидну ( загальну ) ваги = np . масив ( [ 0 , 1 ] ) # w1 = 0, w2 = 1 зміщення = 4 # b = 4 n = нейрон ( ваги , зміщення ) x = np . масив ( [ 2 , 3 ] ) # x1 = 2, x2 = 3 print ( n . feedforward ( x ) ) # 0.9990889488055994 |
Дізнаєтеся числа? Це той же приклад, який розглядався раніше. Відповідь отриманий на цей раз також дорівнює 0.999.
Приклад збір нейронів в нейросеть
Нейронна мережа по суті являє собою групу пов'язаних між собою нейронів. Проста нейронна мережа виглядає наступним чином:
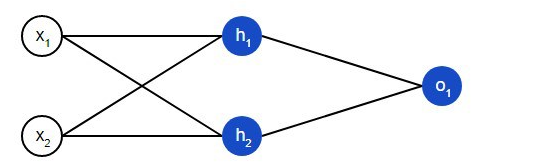
На вступному шарі мережі два входи – x1і x2. На прихованому шарі два нейтрона – h1і h2. На шарі виведення знаходиться один нейрон – о1. Зверніть увагу на те, що вхідні дані для о1є результатами виведення h1і h2. Таким чином і будується нейросеть.
Прихованим шаром називається будь-який шар між вступним шаром і шаром виведення, що є першим і останнім шарами відповідно. Прихованих шарів може бути декілька.
Вихід ŷ простий двошарової нейронної мережі:
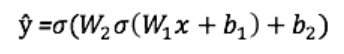
У наведеному вище рівнянні, ваги W і зміщення b є єдиними змінними, які впливають на вихід ŷ.
Природно, правильні значення для ваг і зміщень визначають точність прогнозів. Процес тонкої настройки ваг і зміщень з вхідних даних відомий як навчання нейронної мережі.
Кожна ітерація навчального процесу складається з наступних кроків
- обчислення прогнозованого виходу ŷ, званого прямим поширенням
- оновлення ваг і зміщень, званих зворотним поширенням
Послідовний графік нижче ілюструє процес:

пряме поширення
Як ми бачили на графіку вище, пряме поширення – це просто нескладне обчислення, а для базової 2-шарової нейронної мережі висновок нейронної мережі дається формулою:
Давайте додамо функцію прямого поширення в наш код на Python-е, щоб зробити це. Зауважимо, що для простоти, ми припустили, що зміщення рівні 0.
Однак потрібен спосіб оцінити «добротність» наших прогнозів, тобто наскільки далекі наші прогнози). Функція втрати якраз дозволяє нам зробити це.
функція втрати
Є багато доступних функцій втрат, і характер нашої проблеми повинен диктувати нам вибір функції втрати. У цій роботі ми будемо використовувати суму квадратів помилок в якості опції втрати.

Сума квадратів помилок – це середнє значення різниці між кожним прогнозованим і фактичним значенням.
Мета навчання – знайти набір ваг і зміщень, який мінімізує функцію втрати.
зворотне поширення
Тепер, коли ми виміряли помилку нашого прогнозу (втрати), нам потрібно знайти спосіб поширення помилки назад і відновити наші ваги і зміщення.
Щоб дізнатися відповідну суму для коригування ваг і зміщень, нам потрібно знати похідну функції втрати по відношенню до ваги і зсувів.
Нагадаємо з аналізу, що похідна функції – це тангенс кута нахилу функції.
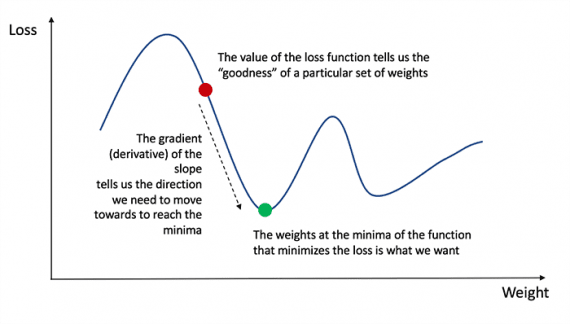
Якщо у нас є похідна, то ми можемо просто оновити ваги і зміщення, збільшивши / зменшивши їх (див. Діаграму вище). Це називається градієнтним спуском.
Однак ми не можемо безпосередньо обчислити похідну функції втрат по відношенню до ваги і зсувів, так як рівняння функції втрат не містить ваг і зміщень. Тому нам потрібно правило ланцюга для допомоги в обчисленні.
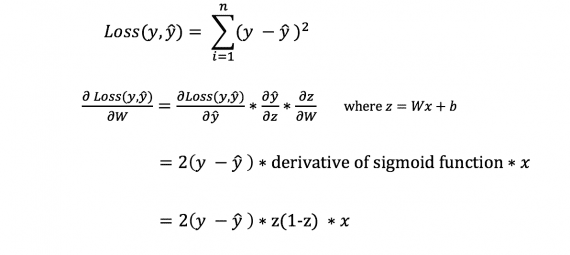
Фух! Це було громіздко, але дозволило отримати те, що нам потрібно – похідну (нахил) функції втрат по відношенню до ваги. Тепер ми можемо відповідним чином регулювати ваги.
Додамо функцію backpropagation (зворотного поширення) в наш код на Python-е:
Приватні похідні
Приватні похідні можна обчислити, тому відомо, який був внесок в помилку по кожному вазі. Необхідність похідних очевидна. Уявіть нейронну мережу, яка намагається знайти оптимальну швидкість безпілотного автомобіля. Eсли машина виявить, що вона їде швидше або повільніше необхідної швидкості, нейронна мережа буде міняти швидкість, прискорюючи або сповільнюючи автомобіль. Що при цьому прискорюється / сповільнюється? Похідні швидкості.
Розберемо необхідність приватних похідних на прикладі.
Припустимо, дітей попросили кинути дротик в мішень, цілячись в центр. Ось результати:

Тепер, якщо ми знайдемо спільну помилку і просто віднімемо її з усіх ваг, ми узагальнимо помилки, допущені кожним. Отже, скажімо, дитина потрапила занадто низько, але ми просимо всіх дітей прагнути потрапляти в ціль, тоді це призведе до наступній картині:
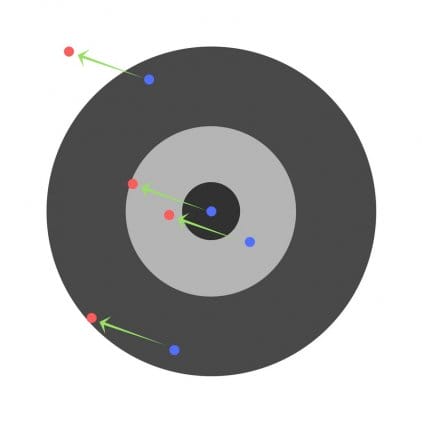
Помилка кількох дітей може зменшитися, але загальна помилка все ще збільшується.
Знайшовши частинні похідні, ми дізнаємося помилки, відповідні кожному вазі окремо. Якщо вибірково виправити ваги, можна отримати наступне:
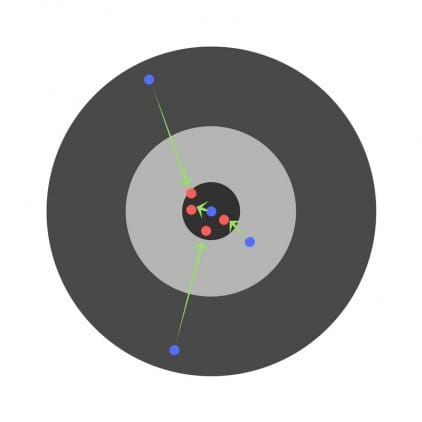
Гіперпараметри
Нейронна мережа використовується для автоматизації відбору ознак, але деякі параметри налаштовуються вручну.
Швидкість навчання є дуже важливим гіперпараметром. Якщо швидкість навчання занадто мала, то навіть після навчання нейронної мережі протягом тривалого часу вона буде далека від оптимальних результатів. Результати будуть виглядати приблизно так:
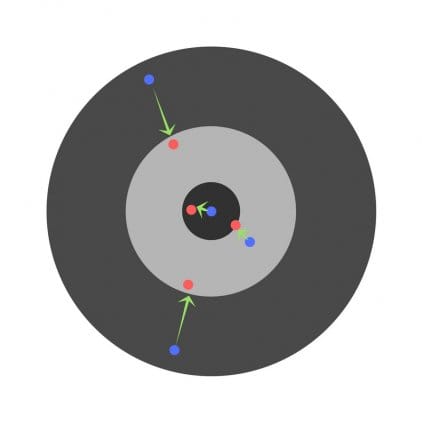
З іншого боку, якщо швидкість навчання занадто висока, то мережу дуже швидко видасть відповіді. Вийде наступне:

Глибокі нейронні мережі
Глибоке навчання (deep learning) – це клас алгоритмів машинного навчання, які навчаються глибше (більш абстрактно) розуміти дані. Популярні алгоритми нейронних мереж глибокого навчання представлені на схемі нижче.
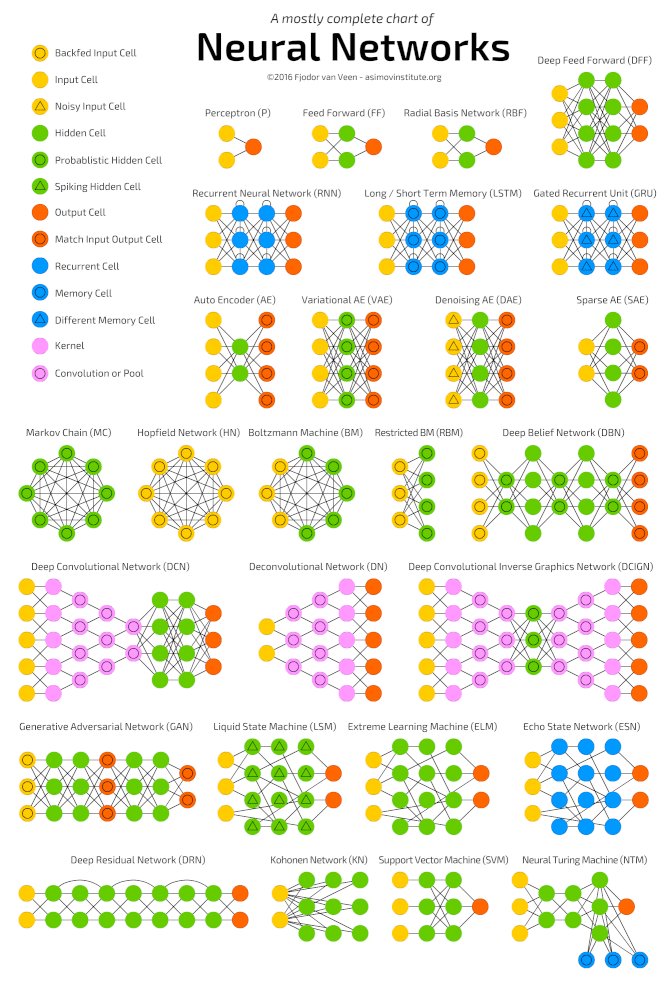
Популярні алгоритми нейронних мереж (http://www.asimovinstitute.org/neural-network-zoo )
Більш формально в deep learning:
- Використовується каскад (пайплайн, як послідовно переданий потік) з безлічі обробних шарів (нелінійних) для вилучення і перетворення ознак;
- Грунтується на вивченні ознак (поданні інформації) в даних без навчання з учителем. Функції вищого рівня (які знаходяться в останніх шарах) виходять з функцій нижнього рівня (які знаходяться в шарах початкових шарах);
- Вивчає багаторівневі уявлення, які відповідають різним рівням абстракції; рівні утворюють ієрархію уявлення.
Тренуємо нейросеть на функції XOR
Чому функція XOR так цікава? Просто тому, що її неможливо отримати одним нейроном: 0 ^ 0 = 0, 0 ^ 1 = 1, 1 ^ 0 = 1, 1 ^ 1 = 0. Однак вона легко виходить збільшенням числа нейронів. Ми ж спробуємо виконати навчання мережі з 3 нейронами в прихованому шарі і 1 вихідним (так як вихід у нас всього один). Для цього нам необхідно створити масив векторів X і Y з навчальними даними і саму нейросеть:
// массив входных обучающих векторов Vector[] X = { new Vector(0, 0), new Vector(0, 1), new Vector(1, 0), new Vector(1, 1) }; // массив выходных обучающих векторов Vector[] Y = { new Vector(0.0), // 0 ^ 0 = 0 new Vector(1.0), // 0 ^ 1 = 1 new Vector(1.0), // 1 ^ 0 = 1 new Vector(0.0) // 1 ^ 1 = 0 }; Network network = new Network(new int[]{2, 3, 1}); // создаём сеть с двумя входами, тремя нейронами в скрытом слое и одним выходом Після чого запустимо навчання з наступними параметрами: швидкість навчання – 0.5, число епох – 100000, величина помилки – 1e-7:
network.Train(X, Y, 0.5, 1e-7, 100000); // запускаем обучение сети Після навчання подивимося на результати вплинув прямий прохід для всіх елементів:
for (int i = 0; i Джерело запису: lastici.ru