Em palavras simples sobre o complexo: o que são redes neurais? Escrevendo uma rede neural feedforward do zero.

Contente
O que é uma rede neural?
Como você sabe, nosso cérebro é uma coisa complexa. A coordenação de seu trabalho ocorre por meio de neurônios – células nervosas com ramos que se estendem a partir deles. Entrelaçando-se entre si, os neurônios formam uma rede neural – um mecanismo intrincado que determina toda a diversidade da psique humana. Esta é a raiz de nossa autoconsciência, o sentimento de nós como indivíduos, guiados por nossos desejos e aspirações interiores.
Se algum tipo de mau funcionamento ocorre no trabalho dos neurônios, a pessoa muda irreconhecível. Dependendo da gravidade da lesão, as mudanças variam de sinais leves de comportamento desviante à cessação do funcionamento normal do corpo. Os danos cerebrais costumam ser fatais.
Mas hoje não vamos falar sobre biologia, porque não apenas o sistema do nosso cérebro é chamado de redes neurais, mas também um programa de computador complexo com princípios operacionais semelhantes. Como a massa cinzenta, é fractal, ou seja, consiste em muitos programas mais simples que formam uma espécie de simbiose.
Enquanto funciona, a rede neural aprende, ganha experiência e se torna mais perfeita. Trata-se, assim, de um verdadeiro organismo digital, que um dia deverá ultrapassar o seu criador.
Como as redes neurais apareceram
O surgimento do conceito de redes neurais artificiais remonta à década de 40 do século anterior. Em particular, está associado aos cientistas McCulloch e Pitts, que tentaram simular os processos do cérebro. Eles também propuseram a ideia de criar um sistema de autoaprendizagem projetado para realizar várias operações lógicas. O problema era que as tecnologias da época estavam longe das de hoje e os inventores não conseguiram concretizar totalmente suas idéias.
(Warren McCulloch e Walter Pitts)
Seu trabalho foi continuado pelo fisiologista canadense Donald Hebb, e em 1949 o primeiro algoritmo para calcular ANN foi apresentado ao mundo. Pelos próximos 10 anos, serviu de base para o desenvolvimento de outros cientistas, até que, finalmente, em 1958, Frank Rosenblatt criou o parceptron, uma tecnologia que imita o trabalho de nossos cérebros. Para a época, essa novidade era incrível. Cientistas soviéticos e americanos se juntaram ao trabalho, que também deram uma contribuição considerável para a pesquisa.
No final do século XX – início do século XXI, a tecnologia deu um salto brusco, que serviu como um bom incentivo para atividades científicas mais intensas, e em 2007 o cientista da computação Jeffrey Hinton desenvolveu um algoritmo de aprendizado profundo para redes neurais, que agora é amplamente utilizado em carros autônomos.

(Geoffrey Hinton)
Um pouco de historia
Pela primeira vez, o conceito de redes neurais artificiais (RNA) surgiu ao tentar simular os processos do cérebro. O primeiro grande avanço nesta área pode ser considerado a criação do modelo de rede neural McCulloch-Pitts em 1943. Os cientistas desenvolveram primeiro um modelo de neurônio artificial. Eles também propuseram a construção de uma rede desses elementos para realizar operações lógicas. Mas o mais importante é que os cientistas provaram que essa rede é capaz de aprender.

O próximo passo importante foi o desenvolvimento por Donald Hebb do primeiro algoritmo para calcular ANN em 1949, que se tornou fundamental para as décadas seguintes. Em 1958, Frank Rosenblatt desenvolveu o parceptron, um sistema que imita os processos do cérebro. Ao mesmo tempo, a tecnologia não tinha análogos e ainda é fundamental nas redes neurais. Em 1986, quase simultaneamente, independentemente um do outro, os cientistas americanos e soviéticos melhoraram significativamente o método fundamental de ensino do perceptron multicamadas. Em 2007, as redes neurais renasceram. Cientista da computação britânico Jeffrey Hinton desenvolveu pela primeira vez um algoritmo de aprendizado profundo para redes neurais multicamadas, que agora é, por exemplo, usado para operar veículos não tripulados.
Resumidamente sobre o principal
No sentido geral da palavra, as redes neurais são modelos matemáticos que funcionam com base no princípio das redes de células nervosas em um organismo animal. ANNs podem ser implementadas em soluções programáveis e de hardware. Para facilitar a percepção, um neurônio pode ser imaginado como um tipo de célula, que tem muitos orifícios de entrada e uma saída. Quantos sinais de entrada são formados no de saída determina o algoritmo de cálculo. Os valores efetivos são alimentados para cada entrada de neurônio, que são então propagados ao longo de conexões interneuronais (sinopse). As sinapses têm um parâmetro – peso, devido ao qual as informações de entrada mudam quando se movem de um neurônio para outro. A maneira mais fácil de imaginar como as redes neurais funcionam pode ser representada pelo exemplo de mistura de cores. Os neurônios azuis, verdes e vermelhos têm pesos diferentes.
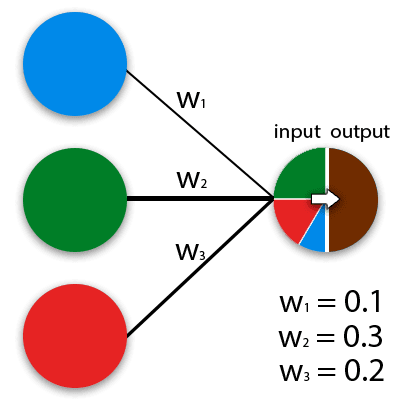
A própria rede neural é um sistema de muitos desses neurônios (processadores). Individualmente, esses processadores são bastante simples (muito mais simples do que um processador de computador pessoal), mas quando conectados a um grande sistema, os neurônios são capazes de realizar tarefas muito complexas.
Dependendo da área de aplicação, uma rede neural pode ser interpretada de diferentes maneiras. Por exemplo, do ponto de vista do aprendizado de máquina, uma RNA é um método de reconhecimento de padrões. Do ponto de vista matemático, este é um problema multiparâmetro. Do ponto de vista da cibernética, é um modelo de controle adaptativo da robótica. Para a inteligência artificial, a RNA é um componente fundamental para modelar a inteligência natural usando algoritmos computacionais.
A principal vantagem das redes neurais sobre os algoritmos de computação convencionais é sua capacidade de aprender. No sentido geral da palavra, a aprendizagem consiste em encontrar os coeficientes de acoplamento corretos entre os neurônios, bem como em generalizar dados e identificar relações complexas entre sinais de entrada e saída. Na verdade, o treinamento bem-sucedido de uma rede neural significa que o sistema será capaz de identificar o resultado correto com base em dados não presentes no conjunto de treinamento.
Aplicação de redes neurais
A gama de aplicação das redes neurais é incrivelmente ampla e é limitada apenas pela nossa imaginação. Vamos listar alguns deles:
- Sistemas automáticos de controle de transporte. Pilotos automáticos.
- A Internet. Assistentes de voz, navegadores inteligentes, programas de tradução.
- Economia e negócios. Previsão de taxas de câmbio, programas de contabilidade modernos, robôs comerciais, programas de avaliação de risco, gerenciamento de máquinas de produção, controle de qualidade, etc.
- Medicamento. Métodos modernos de diagnóstico, análise da eficácia do tratamento, processamento de imagens médicas.
- Robótica. Planejamento de rotas, reconhecimento de fala e gestos.
- Segurança. Gestão de sistemas de videovigilância e alarmes.
- Jogos e entretenimento de computador. Bots inteligentes, programas analíticos para xadrez e outros jogos.
- Arte. Criação de pinturas, livros e outros artefatos culturais.

Situação de hoje
E por mais promissora que essa tecnologia seja, até agora as RNAs ainda estão muito longe das capacidades do cérebro e do pensamento humanos. No entanto, as redes neurais já estão sendo usadas em muitas áreas da atividade humana. Até agora, eles não são capazes de tomar decisões altamente intelectuais, mas são capazes de substituir uma pessoa onde antes ela era necessária. Dentre as inúmeras áreas de aplicação da ANN, pode-se destacar: a criação de sistemas de autoaprendizagem de processos de produção, veículos não tripulados, sistemas de reconhecimento de imagem, sistemas de segurança inteligentes, robótica, sistemas de monitoramento de qualidade, interfaces de interação de voz, sistemas analíticos e muito mais. Esse uso generalizado de redes neurais, entre outras coisas, se deve ao surgimento de várias maneiras de acelerar o aprendizado de RNA.
Hoje, o mercado de redes neurais é enorme – bilhões e bilhões de dólares. Como mostra a prática, a maioria das tecnologias de rede neural em todo o mundo diferem pouco umas das outras. No entanto, o uso de redes neurais é uma tarefa muito cara, que na maioria dos casos apenas grandes empresas podem pagar. Para o desenvolvimento, treinamento e teste de redes neurais, é necessário grande poder de computação, é óbvio que grandes players do mercado de TI já estão fartos disso. Entre as principais empresas líderes de desenvolvimento nesta área estão Google DeepMind, Microsoft Research, IBM, Facebook e Baidu.
Claro, tudo isso é bom: as redes neurais estão se desenvolvendo, o mercado está crescendo, mas até agora a tarefa principal não foi resolvida. A humanidade falhou em criar uma tecnologia que se aproxima em capacidades do cérebro humano. Vamos dar uma olhada nas principais diferenças entre o cérebro humano e as redes neurais artificiais.
Por que as redes neurais ainda estão longe do cérebro humano?
A diferença mais importante, que muda fundamentalmente o princípio e a eficiência do sistema, é a diferente transmissão de sinais em redes neurais artificiais e na rede biológica de neurônios. O fato é que na RNA os neurônios transmitem valores que são valores reais, ou seja, números. No cérebro humano, os impulsos com amplitude fixa são transmitidos, e esses impulsos são quase instantâneos. Conseqüentemente, há uma série de vantagens na rede humana de neurônios.
Primeiro, as linhas de comunicação no cérebro são muito mais eficientes e econômicas do que nas RNAs. Em segundo lugar, o circuito de impulso garante a simplicidade da implementação da tecnologia: basta usar circuitos analógicos em vez de mecanismos computacionais complexos. Em última análise, as redes de impulso são protegidas contra interferência acústica. Os números válidos estão sujeitos a ruído, o que aumenta a chance de ocorrência de erros.
Perspectivas para redes neurais
O movimento ludita começou no início do século XIX. Esta palavra foi usada para descrever as pessoas que participam de protestos contra a urbanização. Com a industrialização da sociedade, quando as máquinas começaram a substituir gradativamente os trabalhadores, muitas pessoas ficaram desempregadas e extremamente insatisfeitas com sua situação. Imaginem que choque eles teriam sentido se soubessem que em algumas centenas de anos as máquinas serão capazes de falar e até mesmo se mover independentemente!
Enquanto isso, esses tempos chegaram e hoje também há retrógrados que temem que a robótica e o desenvolvimento da tecnologia em geral possam fazer uma brincadeira cruel com as pessoas. Afinal, se as máquinas já são capazes de realizar tantas tarefas hoje, no futuro ocuparão todas as funções, tornando as pessoas desnecessárias. E essa posição só é confirmada pelas avaliações de especialistas que, de vez em quando, predizem o desaparecimento iminente de uma determinada profissão.
Esta posição tem o direito de existir, mas não é totalmente correta, pois com o tempo, não só as velhas profissões desaparecem, mas também surgem novas. Sim, há uma ordem de magnitude menos pastores e caçadores do que antes, mas apareceram programadores e profissionais de marketing. Em momentos decisivos da história, a economia se reorienta, eliminando o que é desnecessário e dotando generosamente os que precisam.
A crescente influência das redes neurais artificiais é óbvia e é provável que em breve estarão literalmente em toda parte, mas ter medo disso significa rejeitar a própria natureza humana, que consiste no desejo de descoberta e realização.
Criação de blocos neurais
Primeiro, você precisa decidir quais são os componentes básicos de uma rede neural – neurônios. O neurônio recebe dados de entrada, realiza certas operações matemáticas com eles e, em seguida, produz o resultado. Um neurônio com duas entradas se parece com isto:
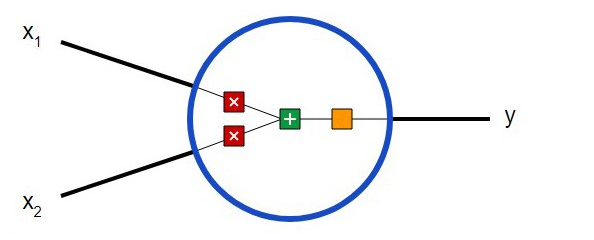
Três coisas estão acontecendo aqui. Primeiro, cada entrada é multiplicada por seu peso (mostrado em vermelho no diagrama ):
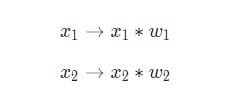
Em seguida, todas as entradas ponderadas são adicionadas juntamente com o deslocamento b(indicado em verde no diagrama ):
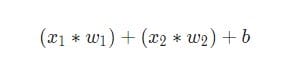
Por fim, o valor é transferido por meio da função de ativação (marcada em amarelo no diagrama ):

A função de ativação é usada para conectar entradas não relacionadas a uma saída de formato simples e previsível. Como regra, a função sigmóide é considerada como a função de ativação usada :
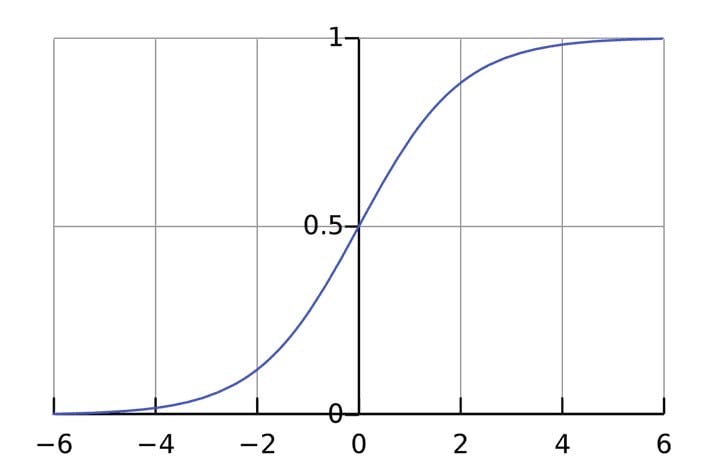
A função sigmóide exibe apenas números em um intervalo (0, 1). Você pode pensar nisso como compactar de (−∞, +∞)para (0, 1). Grandes números negativos tornam-se ~0, e grandes números positivos tornam-se ~1.
Um exemplo simples de como trabalhar com neurônios em Python
Suponha que temos um neurônio com duas entradas que usa uma função de ativação sigmóide e tem os seguintes parâmetros:
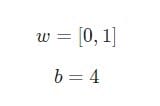
w = [0,1]É apenas uma forma de escrever w1 = 0, w2 = 1em vetor. Vamos atribuir uma entrada com um valor ao neurônio x = [2, 3]. Para uma representação mais compacta, o produto escalar será usado .
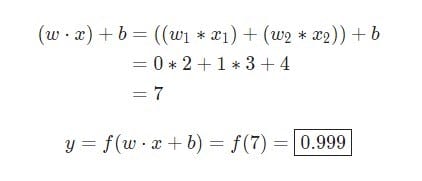
Dado que a entrada foi x = [2, 3], a saída será igual 0.999. Isso é tudo. Esse processo de passar dados de entrada para receber saída é chamado de feedforward.
Construindo um neurônio do zero em Python
Vamos começar a implementar o neurônio. Isso exigirá o uso de NumPy. É uma biblioteca Python computacional poderosa que usa operações matemáticas:
|
1 2 3 quatro cinco 6 7 oito nove 10 onze 12 13 quatorze quinze dezesseis 17 dezoito dezenove vinte 21 22 23 24 25 26 27 |
importar numpy como np def sigmóide ( x ) : # Nossa função de ativação: f (x) = 1 / (1 + e ^ (- x)) retornar 1 / ( 1 + np . exp ( – x ) ) classe Neuron : def __init__ ( self , weight , bias ) : eu . pesos = pesos eu . viés = viés def feedforward ( self , inputs ) : # Insira os dados de peso, adicione o deslocamento # e uso subsequente da função de ativação total = np . ponto ( auto . pesos , entradas ) + auto . tendência retornar sigmóide ( total ) pesos = np . matriz ( [ 0 , 1 ] ) # w1 = 0, w2 = 1 polarização = 4 # b = 4 n = Neurônio ( pesos , polarização ) x = np . matriz ( [ 2 , 3 ] ) # x1 = 2, x2 = 3 imprimir ( n . feedforward ( x ) ) # 0.9990889488055994 |
Você reconhece os números? Este é o mesmo exemplo discutido anteriormente. A resposta recebida desta vez também é igual 0.999.
Um exemplo de coleta de neurônios em uma rede neural
Uma rede neural é essencialmente um grupo de neurônios interconectados. Uma rede neural simples se parece com isto:
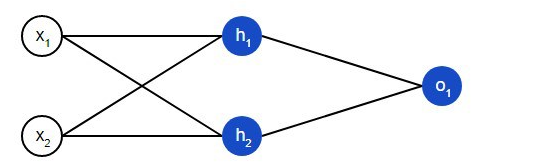
Na camada introdutória da rede, existem duas entradas – x1e x2. Existem dois nêutrons na camada oculta – h1e h2. Há um neurônio na camada de saída – о1. Observe que as entradas para о1são resultados de saída h1e h2. Esta é a forma como a rede neural é construído.
Uma camada oculta é qualquer camada entre a camada de entrada e a camada de saída, que são a primeira e a última camadas, respectivamente. Pode haver várias camadas ocultas.
Treinamento de rede neural
Saída ŷ de uma rede neural simples de duas camadas:
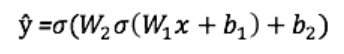
Na equação acima, os pesos W e os vieses b são as únicas variáveis que afetam o produto ŷ.
Naturalmente, os valores corretos para os pesos e vieses determinam a precisão das previsões. O processo de ajuste fino de pesos e vieses dos dados de entrada é conhecido como treinamento de rede neural.
Cada iteração do processo de treinamento consiste nas seguintes etapas
- calcular a saída prevista ŷ chamada de propagação direta
- atualizar pesos e vieses chamados backpropagation
O gráfico sequencial abaixo ilustra o processo:

Distribuição direta
Como vimos no gráfico acima, a propagação direta é apenas um cálculo simples e, para uma rede neural básica de 2 camadas, a saída da rede neural é dada por:
Vamos adicionar feedforward ao nosso código Python para fazer isso. Observe que, para simplificar, assumimos que os deslocamentos são 0.
No entanto, precisamos de uma forma de avaliar a “bondade” de nossas previsões, ou seja, o quão longe nossas previsões estão). A função de perda nos permite fazer exatamente isso.
Função de perda
Existem muitas funções de perda disponíveis, e a natureza do nosso problema deve ditar nossa escolha da função de perda. Neste artigo, usaremos a soma dos quadrados dos erros como a função de perda.

A soma dos erros quadrados é a média da diferença entre cada valor previsto e o valor real.
O objetivo do treinamento é encontrar um conjunto de pesos e vieses que minimizem a função de perda.
Propagação de volta
Agora que medimos nosso erro de previsão (perdas), precisamos encontrar uma maneira de propagar o erro de volta e atualizar nossos pesos e vieses.
Para descobrir o valor apropriado para corrigir os pesos e vieses, precisamos saber a derivada da função de perda com relação aos pesos e vieses.
Lembre-se da análise que a derivada de uma função é a tangente da inclinação da função.
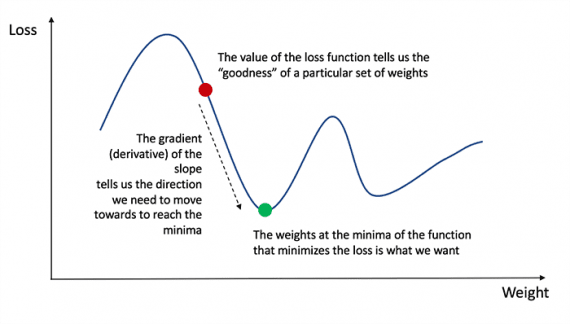
Se tivermos uma derivada, podemos simplesmente atualizar os pesos e vieses aumentando / diminuindo-os (consulte o diagrama acima). Isso é chamado de descida gradiente.
No entanto, não podemos calcular diretamente a derivada da função de perda com relação aos pesos e vieses, uma vez que a equação da função de perda não contém pesos e vieses. Portanto, precisamos de uma regra em cadeia para auxiliar no cálculo.
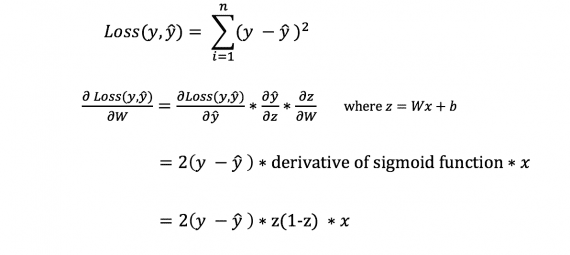
Fuh! Era complicado, mas nos permitiu obter o que precisamos – a derivada (inclinação) da função de perda em relação aos pesos. Agora podemos ajustar os pesos de acordo.
Vamos adicionar a função backpropagation ao nosso código Python:
Derivadas parciais
Derivadas parciais podem ser calculadas, para que se saiba qual foi a contribuição para o erro de cada peso. A necessidade de derivados é óbvia. Imagine uma rede neural tentando encontrar a velocidade ideal para um veículo autônomo. Se o carro detectar que está indo mais rápido ou mais devagar do que a velocidade necessária, a rede neural mudará a velocidade, acelerando ou desacelerando o carro. O que está acelerando / desacelerando ao mesmo tempo? Derivadas de velocidade.
Vejamos a necessidade de derivadas parciais usando um exemplo.
Suponha que as crianças sejam solicitadas a lançar um dardo em um alvo, visando o centro. Aqui estão os resultados:

Agora, se encontrarmos um erro geral e simplesmente subtraí-lo de todos os pesos, resumiremos os erros cometidos por cada um. Então, digamos que a criança bateu muito baixo, mas pedimos a todas as crianças que se esforcem para atingir o alvo, então isso levará à seguinte imagem:
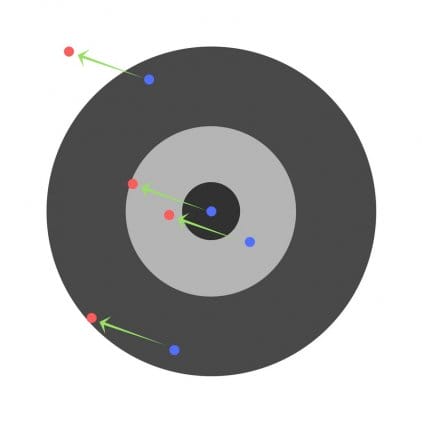
O erro de várias crianças pode diminuir, mas o erro total ainda está aumentando.
Tendo encontrado as derivadas parciais, encontramos os erros correspondentes a cada peso separadamente. Se você corrigir seletivamente os pesos, obterá o seguinte:
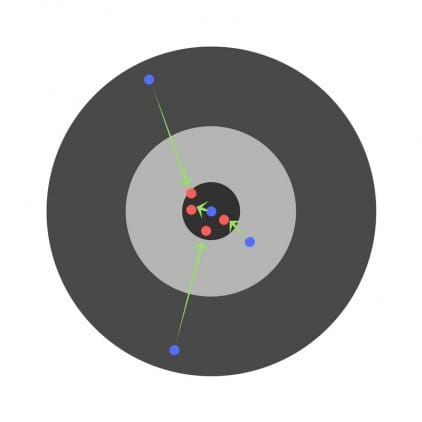
Hiperparâmetros
Uma rede neural é usada para automatizar a seleção de recursos, mas alguns parâmetros são configurados manualmente.
Taxa de Aprendizagem
A taxa de aprendizagem é um hiperparâmetro muito importante. Se a taxa de aprendizado for muito baixa, mesmo depois de treinar a rede neural por um longo tempo, os resultados estarão longe de serem ótimos. Os resultados serão mais ou menos assim:
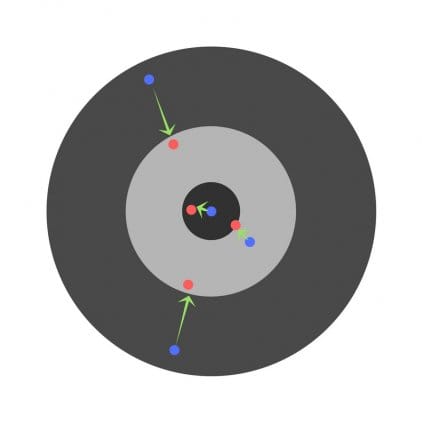
Por outro lado, se a taxa de aprendizado for muito alta, a rede responderá muito rapidamente. O resultado é o seguinte:

Redes neurais profundas
Aprendizado profundo é uma classe de algoritmos de aprendizado de máquina que aprendem a entender os dados mais profundamente (de forma mais abstrata). Algoritmos populares para redes neurais de aprendizado profundo são apresentados no diagrama abaixo.
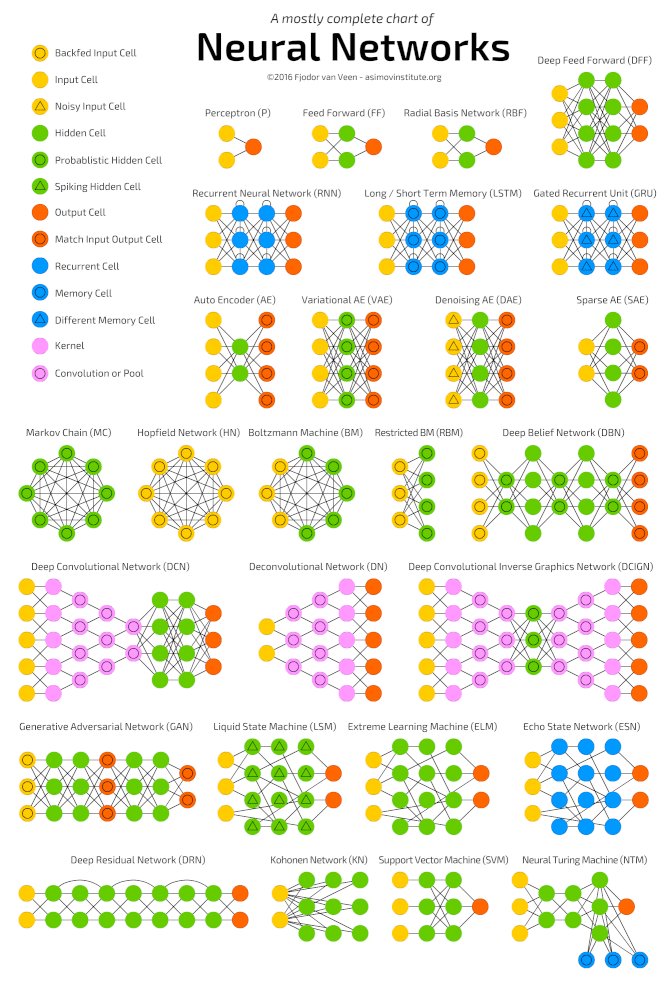
Algoritmos de rede neural populares (http://www.asimovinstitute.org/neural-network-zoo )
Mais formalmente na aprendizagem profunda:
- Uma cascata (pipeline, como um fluxo transmitido sequencialmente) é usada a partir de uma variedade de camadas de processamento (não linear) para extrair e transformar recursos;
- Baseado no estudo de características (apresentação de informações) em dados sem aprendizagem supervisionada. As funções de nível superior (que estão nas últimas camadas) são obtidas a partir das funções de nível inferior (que estão nas camadas das camadas iniciais);
- Explora visualizações em camadas que correspondem a diferentes níveis de abstração; níveis formam uma hierarquia de apresentação.
Treine a rede neural usando funções XOR
Por que a função XOR é tão interessante? Simplesmente porque não pode ser obtido por um neurônio: 0 ^ 0 = 0, 0 ^ 1 = 1, 1 ^ 0 = 1, 1 ^ 1 = 0. No entanto, é facilmente obtido aumentando o número de neurônios. Tentaremos treinar uma rede com 3 neurônios na camada oculta e 1 saída (já que temos apenas uma saída). Para fazer isso, precisamos criar uma matriz de vetores X e Y com dados de treinamento e a própria rede neural:
// массив входных обучающих векторов Vector[] X = { new Vector(0, 0), new Vector(0, 1), new Vector(1, 0), new Vector(1, 1) }; // массив выходных обучающих векторов Vector[] Y = { new Vector(0.0), // 0 ^ 0 = 0 new Vector(1.0), // 0 ^ 1 = 1 new Vector(1.0), // 1 ^ 0 = 1 new Vector(0.0) // 1 ^ 1 = 0 }; Network network = new Network(new int[]{2, 3, 1}); // создаём сеть с двумя входами, тремя нейронами в скрытом слое и одним выходом Em seguida, começamos o treinamento com os seguintes parâmetros: taxa de aprendizagem – 0,5, número de épocas – 100.000, valor de erro – 1e-7:
network.Train(X, Y, 0.5, 1e-7, 100000); // запускаем обучение сети Após o treinamento, vamos ver os resultados realizando uma passagem direta para todos os elementos:
for (int i = 0; i Fonte de gravação: lastici.ru