In simple words about the complex: what are neural networks? Writing a feedforward neural network from scratch.

Content
What is a neural network?
As you know, our brain is a complex thing. The coordination of its work occurs through neurons – nerve cells with branches extending from them. Intertwining with each other, neurons form a neural network – an intricate mechanism that determines all the diversity of the human psyche. This is the root of our self-awareness, the feeling of us as individuals, guided by our inner desires and aspirations.
If a malfunction occurs in the work of neurons, the person changes beyond recognition. Depending on the severity of the injury, the changes range from mild signs of deviant behavior to the cessation of normal body functioning. Brain damage is often fatal.
But today we will not talk about biology, because not only the system of our brain is called neural networks, but also a complex computer program with similar operating principles. Like gray matter, it is fractal, that is, it consists of many simpler programs that form a kind of symbiosis.
While functioning, the neural network learns, gains experience and becomes more perfect. Thus, we are dealing with a real digital organism, which is predicted to one day surpass its creator.
How neural networks appeared
The emergence of the concept of artificial neural networks dates back to the 40s of the previous century. In particular, it is associated with scientists McCulloch and Pitts, who tried to simulate the processes of the brain. They also proposed the idea of creating a self-learning system designed to perform various logical operations. The problem was that the technologies of that time were far from those of today, and the inventors failed to fully realize their ideas.
(Warren McCulloch & Walter Pitts)
Their work was continued by the Canadian physiologist Donald Hebb, and in 1949 the first algorithm for computing ANN was presented to the world. For the next 10 years, it served as a base for the development of other scientists, until, finally, in 1958, Frank Rosenblatt created the parceptron, a technology that mimics the work of our brains. For its time, this novelty was incredible. Soviet and American scientists joined the work, who also made a considerable contribution to the research.
In the late XX – early XXI centuries, technology made a sharp leap, which served as a good incentive for more intensive scientific activity, and in 2007 computer scientist Jeffrey Hinton came up with a deep learning algorithm for neural networks, which is now widely used in self-driving cars.

(Geoffrey Hinton)
A bit of history
For the first time, the concept of artificial neural networks (ANNs) arose when trying to simulate the processes of the brain. The first major breakthrough in this area can be considered the creation of the McCulloch-Pitts neural network model in 1943. Scientists first developed a model of an artificial neuron. They also proposed the construction of a network of these elements to perform logical operations. But most importantly, scientists have proven that such a network is capable of learning.

The next important step was the development by Donald Hebb of the first algorithm for computing ANN in 1949, which became fundamental for the next several decades. In 1958, Frank Rosenblatt developed the parceptron, a system that mimics the processes of the brain. At one time, the technology had no analogues and is still fundamental in neural networks. In 1986, almost simultaneously, independently of each other, American and Soviet scientists significantly improved the fundamental method of teaching the multilayer perceptron. In 2007, neural networks underwent a rebirth. British computer scientist Jeffrey Hinton first developed a deep learning algorithm for multilayer neural networks, which is now, for example, used to operate unmanned vehicles.
Briefly about the main
In the general sense of the word, neural networks are mathematical models that work on the principle of networks of nerve cells in an animal organism. ANNs can be implemented in both programmable and hardware solutions. For ease of perception, a neuron can be imagined as a kind of cell, which has many input holes and one output. How numerous incoming signals are formed into outgoing ones determines the calculation algorithm. Effective values are fed to each neuron input, which are then propagated along interneuronal connections (synopsis). Synapses have one parameter – weight, due to which the input information changes when moving from one neuron to another. The easiest way to imagine how neural networks work can be represented by the example of color mixing. The blue, green, and red neurons have different weights.
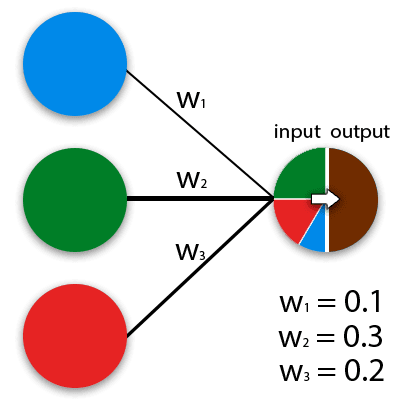
The neural network itself is a system of many such neurons (processors). Individually, these processors are quite simple (much simpler than a personal computer processor), but when connected into a large system, neurons are capable of performing very complex tasks.
Depending on the area of application, a neural network can be interpreted in different ways.For example, from the point of view of machine learning, an ANN is a pattern recognition method. From a mathematical point of view, this is a multi-parameter problem. From the point of view of cybernetics, it is a model of adaptive control of robotics. For artificial intelligence, ANN is a fundamental component for modeling natural intelligence using computational algorithms.
The main advantage of neural networks over conventional computation algorithms is their ability to learn. In the general sense of the word, learning consists in finding the correct coupling coefficients between neurons, as well as in generalizing data and identifying complex relationships between input and output signals. In fact, successful training of a neural network means that the system will be able to identify the correct result based on data not present in the training set.
Application of neural networks
The range of applications for neural networks is incredibly wide and is limited only by our imagination. Let's list some of them:
- Automatic transport control systems. Autopilots.
- The Internet. Voice assistants, smart browsers, translation programs.
- Economy and business. Forecasting exchange rates, modern accounting programs, trading robots, risk assessment programs, management of production machines, quality control, etc.
- Medicine. Modern methods of diagnosing, analyzing the effectiveness of treatment, processing medical images.
- Robotics. Route planning, speech and gesture recognition.
- Safety. Video surveillance and alarm systems management.
- Computer games and entertainment. Smart bots, analytical programs for chess and other games.
- Art. Creation of paintings, books and other cultural artifacts.

Today's situation
And no matter how promising this technology would be, so far ANNs are still very far from the capabilities of the human brain and thinking. Nevertheless, neural networks are already being used in many areas of human activity. So far, they are not able to make highly intellectual decisions, but they are able to replace a person where he was previously needed. Among the numerous areas of ANN application, one can note: the creation of self-learning systems of production processes, unmanned vehicles, image recognition systems, intelligent security systems, robotics, quality monitoring systems, voice interaction interfaces, analytics systems and much more. Such widespread use of neural networks is, among other things, due to the emergence of various ways to accelerate the learning of ANN.
Today the market for neural networks is huge – it is billions and billions of dollars. As practice shows, most of the technologies of neural networks around the world differ little from each other. However, the use of neural networks is a very expensive undertaking, which in most cases can only be afforded by large companies. For the development, training and testing of neural networks, large computing power is required, it is obvious that large players in the IT market have enough of this. Among the main companies leading development in this area are Google's DeepMind division, Microsoft Research division, IBM, Facebook and Baidu.
Of course, all this is good: neural networks are developing, the market is growing, but so far the main task has not been solved. Humanity has failed to create a technology that is even close in capabilities to the human brain. Let's take a look at the main differences between the human brain and artificial neural networks.
Why are neural networks still far from the human brain?
The most important difference, which fundamentally changes the principle and efficiency of the system, is the different signal transmission in artificial neural networks and in the biological network of neurons. The fact is that in the ANN, neurons transmit values that are real values, that is, numbers. In the human brain, impulses with a fixed amplitude are transmitted, and these impulses are almost instantaneous. This leads to a number of advantages of the human neuronal network.
First, communication lines in the brain are much more efficient and economical than in ANNs. Secondly, the impulse circuit ensures the simplicity of the technology implementation: it is enough to use analog circuits instead of complex computing mechanisms. Ultimately, impulse networks are protected from acoustic interference. Valid numbers are subject to noise, which increases the chance of error occurring.
Prospects for neural networks
The Luddite movement began in the early 19th century. This word was used to describe people participating in protests against urbanization. With the industrialization of society, when machine tools began to gradually replace workers, many people were left out of work and were extremely dissatisfied with their situation. Just imagine what a shock they would have experienced if they learned that in a couple of hundred years the machines will be able to talk and even move independently!
Meanwhile, these times have come, and today there are also retrogrades who fear that robotics and the development of technology in general can play a cruel joke with people. After all, if machines are already capable of performing so many tasks today, in the future they will occupy all jobs, making people unnecessary. And this position is only confirmed by the assessments of experts who now and then predict the imminent disappearance of a particular profession.
This position has the right to exist, but it is not entirely correct, since over time, not only old professions disappear, but new ones also appear. Yes, there are an order of magnitude less shepherds and hunters than before, but programmers and marketers have appeared. At turning points in history, the economy reorients itself, weeding out the unnecessary and generously endowing those in demand.
The growing influence of artificial neural networks is obvious, and it is likely that soon they will be literally everywhere, but to be afraid of this means rejecting human nature itself, which consists in the desire for discovery and achievement.
Creation of neural blocks
First, you need to decide what the basic components of a neural network – neurons – are. The neuron takes input data, performs certain mathematical operations with it, and then outputs the result. A neuron with two inputs looks like this:
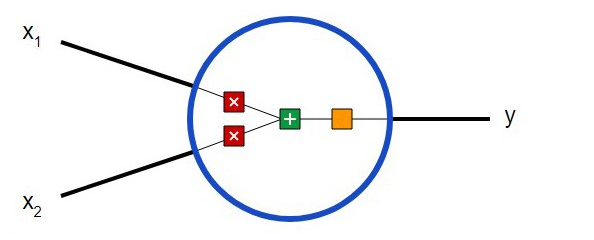
Three things are happening here. First, each input is multiplied by the weight (in the diagram it is marked in red ):
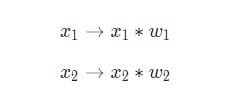
Then all the weighted inputs are added together with the offset b(indicated in green in the diagram ):
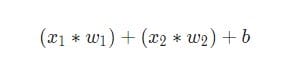
Finally, the amount is transferred through the activation function (marked in yellow in the diagram ):

The activation function is used to connect unrelated inputs to an output that has a simple and predictable shape. As a rule, the sigmoid function is taken as the activation function used :
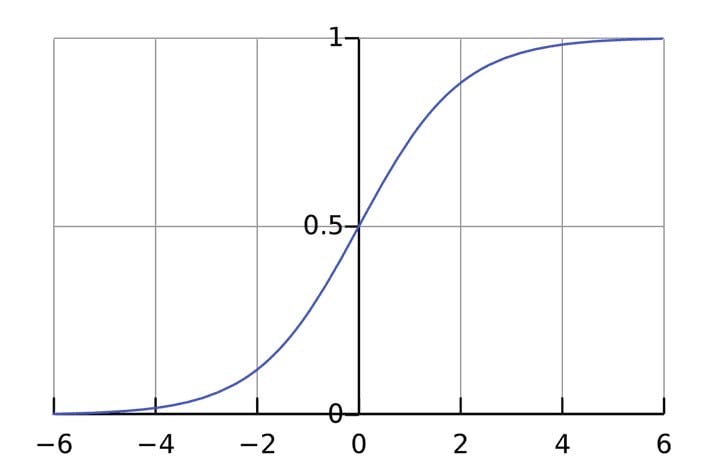
The sigmoid function only outputs numbers in a range (0, 1). You can think of it as compressing from (−∞, +∞)to (0, 1). Large negative numbers become ~0, and large positive numbers become ~1.
A simple example of working with neurons in Python
Suppose we have a neuron with two inputs that uses a sigmoid activation function and has the following parameters:
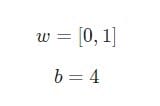
w = [0,1]Is just one way of writing w1 = 0, w2 = 1in vector form. Let's assign an input with a value to the neuron x = [2, 3]. For a more compact representation, the dot product will be used .
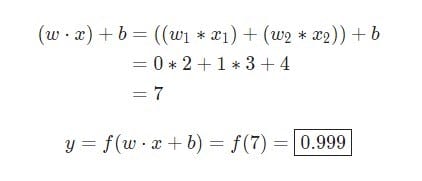
Given that the input was x = [2, 3], the output will be equal 0.999. That's all. This process of passing input data to receive output is called feedforward.
Building a neuron from scratch in Python
Let's start implementing the neuron. This will require the use of NumPy. It is a powerful computational Python library that uses mathematical operations:
|
one 2 3 four five 6 7 eight nine 10 eleven 12 13 fourteen fifteen sixteen 17 eighteen nineteen twenty 21 22 23 24 25 26 27 |
import numpy as np def sigmoid(x): # Our activation function: f (x) = 1 / (1 + e ^ (- x)) return 1 / (1 + np.exp(–x)) class Neuron: def __init__(self, weights, bias): self.weights = weights self.bias = bias def feedforward(self, inputs): # Input weight data, add offset # and subsequent use of the activation function total = np.dot(self.weights, inputs) + self.bias return sigmoid(total) weights = np.array([0, 1]) # w1 = 0, w2 = 1 bias = 4 # b = 4 n = Neuron(weights, bias) x = np.array([2, 3]) # x1 = 2, x2 = 3 print(n.feedforward(x)) # 0.9990889488055994 |
Do you recognize the numbers? This is the same example discussed earlier. The answer received this time is also equal 0.999.
An example of collecting neurons in a neural network
A neural network is essentially a group of interconnected neurons. A simple neural network looks like this:
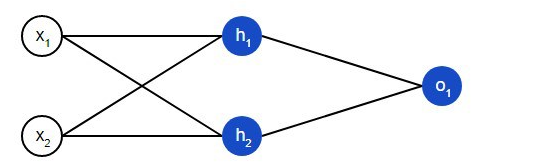
On the introductory layer of the network, there are two entrances – x1and x2. There are two neutrons on the hidden layer – h1and h2. There is one neuron on the output layer – о1. Note that the inputs to о1are output results h1and h2. This is how the neural network is built.
A hidden layer is any layer between the input layer and the output layer, which are the first and last layers, respectively. There can be several hidden layers.
Neural network training
Output ŷ of a simple two-layer neural network:
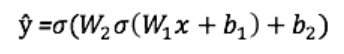
In the above equation, the weights W and the biases b are the only variables that affect the output ŷ.
Naturally, the correct values for the weights and biases determine the accuracy of the predictions. The process of fine-tuning weights and biases from input data is known as neural network training.
Each iteration of the training process consists of the following steps
- calculating the predicted output ŷ called forward propagation
- updating weights and biases called backpropagation
The sequential graph below illustrates the process:

Direct distribution
As we saw in the graph above, forward propagation is just an easy computation, and for a basic 2-layer neural network, the output of the neural network is given by:
Let's add feed forward to our Python code to do this. Note that for simplicity, we have assumed that the offsets are 0.
However, we need a way to assess the “goodness” of our forecasts, that is, how far our forecasts are). The loss function allows us to do just that.
Loss function
There are many loss functions available, and the nature of our problem should dictate our choice of loss function. In this paper, we will use the sum of the squares of the errors as the loss function.

The sum of squared errors is the average of the difference between each predicted value and the actual value.
The goal of training is to find a set of weights and biases that minimizes the loss function.
Back propagation
Now that we have measured our forecast error (losses), we need to find a way to propagate the error back and update our weights and biases.
To find out the appropriate amount to correct for the weights and biases, we need to know the derivative of the loss function with respect to the weights and biases.
Recall from the analysis that the derivative of a function is the tangent of the slope of the function.
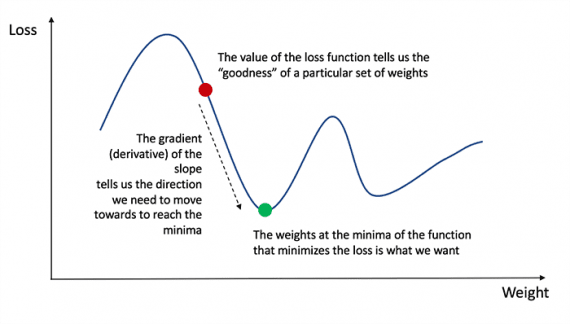
If we have a derivative, then we can simply update the weights and biases by increasing / decreasing them (see diagram above). This is called gradient descent.
However, we cannot directly calculate the derivative of the loss function with respect to weights and biases, since the equation of the loss function does not contain weights and biases. Therefore, we need a chain rule to aid in the calculation.
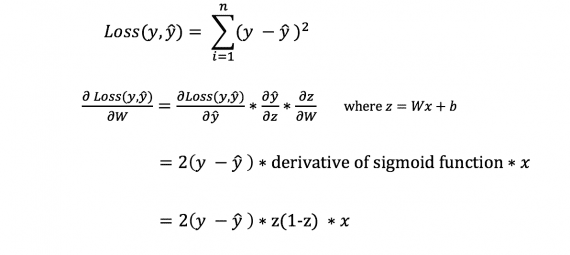
Fuh! It was cumbersome, but it allowed us to get what we need – the derivative (slope) of the loss function with respect to the weights. We can now adjust the weights accordingly.
Let's add the backpropagation function to our Python code:
Partial derivatives
Partial derivatives can be calculated, so it is known what was the contribution to the error for each weight. The need for derivatives is obvious. Imagine a neural network trying to find the optimal speed for an autonomous vehicle. If the car detects that it is going faster or slower than the required speed, the neural network will change the speed, accelerating or decelerating the car. What is accelerating / decelerating at the same time? Velocity derivatives.
Let's look at the need for partial derivatives using an example.
Suppose the children are asked to throw a dart at a target while aiming at the center. Here are the results:

Now, if we find a general error and simply subtract it from all weights, we will summarize the errors made by each. So, let's say the child hit too low, but we ask all children to strive to hit the target, then this will lead to the following picture:
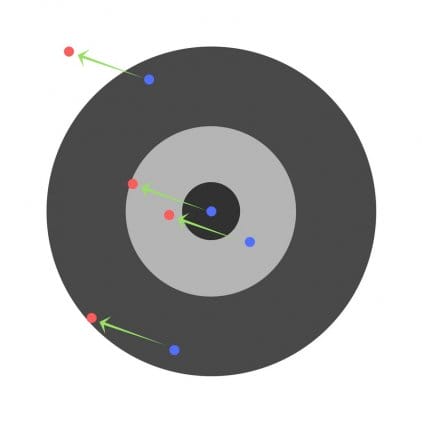
The error of several children may decrease, but the total error is still increasing.
Having found the partial derivatives, we find out the errors corresponding to each weight separately. If you selectively correct the weights, you can get the following:
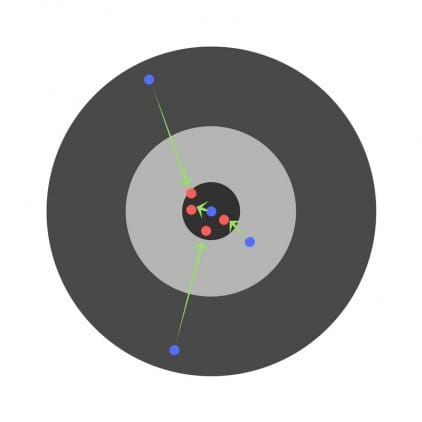
Hyperparameters
A neural network is used to automate feature selection, but some parameters are manually configured.
Learning rate
Learning rate is a very important hyperparameter. If the learning rate is too low, then even after training the neural network for a long time, it will be far from optimal results. The results will look something like this:
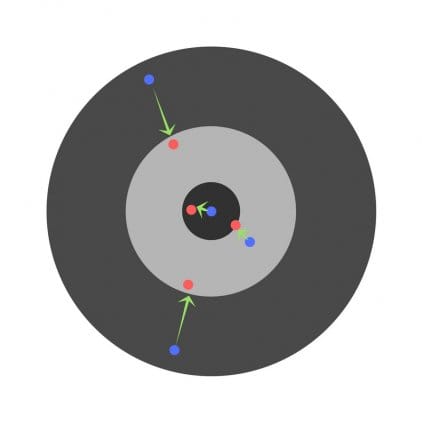
On the other hand, if the learning rate is too high, then the network will respond very quickly. The result is the following:

Deep neural networks
Deep learning is a class of machine learning algorithms that learn to understand data more deeply (more abstractly). Popular algorithms for deep learning neural networks are presented in the diagram below.
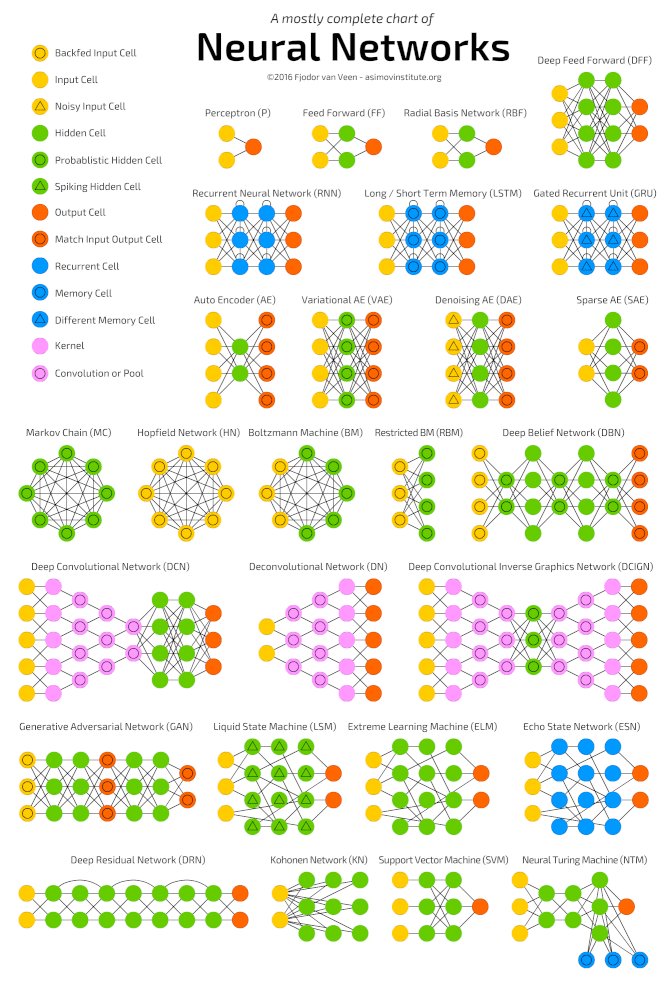
Popular neural network algorithms (http://www.asimovinstitute.org/neural-network-zoo )
More formally in deep learning:
- A cascade (pipeline, as a sequentially transmitted stream) of a plurality of processing layers (nonlinear) is used to extract and transform features;
- Based on the study of features (presentation of information) in data without supervised learning. The higher-level functions (which are in the last layers) are obtained from the lower-level functions (which are in the layers of the initial layers);
- Explores layered views that correspond to different levels of abstraction; levels form a presentation hierarchy.
Train the neural network using XOR functions
Why is the XOR function so interesting? Simply because it cannot be obtained by one neuron: 0 ^ 0 = 0, 0 ^ 1 = 1, 1 ^ 0 = 1, 1 ^ 1 = 0. However, it is easily obtained by increasing the number of neurons. We will try to train a network with 3 neurons in the hidden layer and 1 output (since we have only one output). To do this, we need to create an array of X and Y vectors with training data and the neural network itself:
// массив входных обучающих векторов Vector[] X = { new Vector(0, 0), new Vector(0, 1), new Vector(1, 0), new Vector(1, 1) }; // массив выходных обучающих векторов Vector[] Y = { new Vector(0.0), // 0 ^ 0 = 0 new Vector(1.0), // 0 ^ 1 = 1 new Vector(1.0), // 1 ^ 0 = 1 new Vector(0.0) // 1 ^ 1 = 0 }; Network network = new Network(new int[]{2, 3, 1}); // создаём сеть с двумя входами, тремя нейронами в скрытом слое и одним выходом Then we start training with the following parameters: learning rate – 0.5, number of epochs – 100000, error value – 1e-7:
network.Train(X, Y, 0.5, 1e-7, 100000); // запускаем обучение сети After training, let's look at the results by performing a direct pass for all elements:
for (int i = 0; i Post source: lastici.ru