Med enkla ord om komplexet: vad är neurala nätverk? Skriva ett feedforward neuralt nätverk från grunden.

Innehåll
Vad är ett neuralt nätverk?
Som du vet är vår hjärna en komplex sak. Koordineringen av dess arbete sker genom nervceller – nervceller med grenar som sträcker sig från dem. Sammanflätade med varandra bildar neuroner ett neuralt nätverk – en invecklad mekanism som bestämmer all mångfald i den mänskliga psyken. Detta är roten till vår självmedvetenhet, känslan av oss som individer, styrda av våra inre önskningar och ambitioner.
Om en funktionsstörning inträffar i neuronernas arbete ändras personen utan att känna igen. Beroende på skadans svårighetsgrad varierar förändringarna från milda tecken på avvikande beteende till upphörande av kroppens normala funktion. Hjärnskador är ofta dödliga.
Men idag kommer vi inte att prata om biologi, för inte bara hjärnsystemet kallas neurala nätverk utan också ett komplext datorprogram med liknande funktionsprinciper. Liksom grå substans är den fraktal, det vill säga den består av många enklare program som bildar ett slags symbios.
Samtidigt som det neurala nätverket fungerar lär sig det, får erfarenhet och blir mer perfekt. Således har vi att göra med en riktig digital organism, som förutspås en dag överträffa dess skapare.
Hur neurala nätverk uppträdde
Framväxten av begreppet artificiella neurala nätverk går tillbaka till 40-talet av föregående århundrade. I synnerhet är det associerat med forskarna McCulloch och Pitts, som försökte simulera hjärnans processer. De föreslog också idén att skapa ett självlärande system som är utformat för att utföra olika logiska operationer. Problemet var att den tekniken vid den tiden var långt ifrån den i dag, och uppfinnarna misslyckades med att fullt ut förverkliga sina idéer.
(Warren McCulloch & Walter Pitts)
Deras arbete fortsatte av den kanadensiska fysiologen Donald Hebb, och 1949 presenterades den första algoritmen för beräkning av ANN för världen. Under de kommande tio åren fungerade den som en bas för utvecklingen av andra forskare, tills slutligen 1958 skapade Frank Rosenblatt parceptronen, en teknik som efterliknar vårt hjärnans arbete. För sin tid var denna nyhet otrolig. Sovjetiska och amerikanska forskare gick med i arbetet, som också gjorde ett betydande bidrag till forskningen.
I slutet av XX – tidigt XXI århundraden gjorde tekniken ett kraftigt steg, vilket fungerade som ett bra incitament för mer intensiv vetenskaplig aktivitet, och 2007 kom datavetenskapsmannen Jeffrey Hinton fram med en djupinlärningsalgoritm för neurala nätverk, som nu ofta används i självkörande bilar.

(Geoffrey Hinton)
Lite historia
För första gången uppstod begreppet artificiella neurala nätverk (ANN) när man försökte simulera hjärnans processer. Det första stora genombrottet inom detta område kan betraktas som skapandet av McCulloch-Pitts neurala nätverksmodell 1943. Forskare utvecklade först en modell av en artificiell neuron. De föreslog också byggandet av ett nätverk av dessa element för att utföra logiska operationer. Men viktigast av allt har forskare visat att ett sådant nätverk kan lära sig.

Nästa viktiga steg var utvecklingen av Donald Hebb av den första algoritmen för beräkning av ANN 1949, som blev grundläggande under de kommande decennierna. 1958 utvecklade Frank Rosenblatt parceptron, ett system som efterliknar hjärnans processer. Vid en tidpunkt hade tekniken inga analoger och är fortfarande grundläggande i neurala nätverk. 1986, nästan samtidigt, oberoende av varandra, förbättrade amerikanska och sovjetiska forskare avsevärt den grundläggande metoden att lära ut flerskiktsperseptronen. År 2007 genomgick neurala nätverk en återfödelse. Brittisk datavetare Jeffrey Hinton utvecklade först en djupinlärningsalgoritm för multilayer neurala nätverk, som nu till exempel används för att driva obemannade fordon.
Kort om det viktigaste
I ordets allmänna bemärkelse är neurala nätverk matematiska modeller som fungerar på principen om nätverk av nervceller i en djurorganism. ANN kan implementeras i både programmerbara och hårdvarulösningar. För att underlätta uppfattningen kan en neuron representeras som en viss cell, som har många ingångshål och ett utgångshål. Hur många inkommande signaler formas till utgående signaler bestämmer beräkningsalgoritmen. Effektiva värden matas till varje neuroningång, som sedan förökas längs internuronala anslutningar (synopsis). Synapser har en parameter – vikt, beroende på vilken ingångsinformationen ändras när man flyttar från en neuron till en annan. Det enklaste sättet att föreställa sig hur neurala nätverk fungerar kan representeras av exemplet med färgblandning. De blå, gröna och röda nervcellerna har olika vikter.
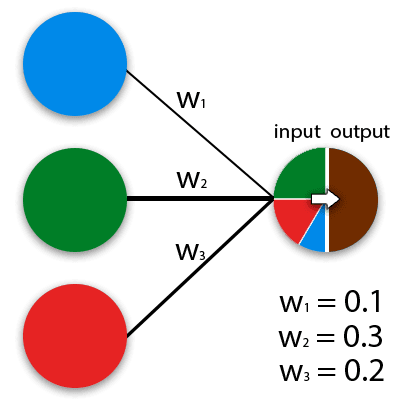
Neurala nätverket i sig är ett system av många sådana neuroner (processorer). Individuellt är dessa processorer ganska enkla (mycket enklare än en persondatorprocessor), men när de är anslutna till ett stort system kan neuroner utföra mycket komplexa uppgifter.
Beroende på applikationsområde kan ett neuralt nätverk tolkas på olika sätt. Till exempel, ur maskininlärningssynpunkt är en ANN en mönsterigenkänningsmetod. Ur en matematisk synvinkel är detta ett problem med flera parametrar. Ur cybernetics synvinkel är det en modell för adaptiv kontroll av robotik. För artificiell intelligens är ANN en grundläggande komponent för modellering av naturlig intelligens med hjälp av beräkningsalgoritmer.
Den största fördelen med neurala nätverk jämfört med konventionella beräkningsalgoritmer är deras förmåga att lära sig. I ordets allmänna bemärkelse består inlärning i att hitta rätt kopplingskoefficienter mellan nervceller, såväl som att generalisera data och identifiera komplexa beroenden mellan in- och utsignaler. Faktum är att framgångsrik träning av ett neuralt nätverk innebär att systemet kommer att kunna identifiera rätt resultat baserat på data som inte finns i träningsuppsättningen.
Tillämpning av neurala nätverk
Användningsområdet för neurala nätverk är otroligt stort och begränsas endast av vår fantasi. Låt oss lista några av dem:
- Automatiska transportsystem. Autopiloter.
- Internet. Röstassistenter, smarta webbläsare, översättningsprogram.
- Ekonomi och affärer. Prognoser för växelkurser, moderna redovisningsprogram, handelsrobotar, riskbedömningsprogram, hantering av produktionsmaskiner, kvalitetskontroll etc.
- Medicin. Moderna metoder för att diagnostisera, analysera effektiviteten av behandlingen, bearbeta medicinska bilder.
- Robotik. Ruttplanering, tal- och gestigenkänning.
- Säkerhet. Videoövervakning och hantering av larmsystem.
- Datorspel och underhållning. Smarta bots, analytiska program för schack och andra spel.
- Konst. Skapande av målningar, böcker och andra kulturella artefakter.

Dagens situation
Oavsett hur lovande den här tekniken skulle vara, så långt är ANN fortfarande mycket långt ifrån den mänskliga hjärnans och tänkandens förmåga. Ändå används neurala nätverk redan inom många områden av mänsklig aktivitet. Hittills kan de inte fatta mycket intellektuella beslut, men de kan ersätta en person där han tidigare behövdes. Bland de många områdena i ANN-applikationen kan man notera: skapandet av självlärande system för produktionsprocesser, obemannade fordon, bildigenkänningssystem, intelligenta säkerhetssystem, robotik, kvalitetsövervakningssystem, röstinteraktionsgränssnitt, analyssystem och mycket mer. Sådan utbredd användning av neurala nätverk, bland annat, beror på framväxten av olika sätt att påskynda inlärningen av ANN.
Idag är marknaden för neurala nätverk enorm – det är miljarder och miljarder dollar. Som praxis visar skiljer sig de flesta av neurologiska nätverkens teknologier runt om i världen lite från varandra. Användningen av neurala nätverk är dock ett mycket dyrt åtagande, som i de flesta fall endast kan erbjudas av stora företag. För utveckling, utbildning och testning av neurala nätverk krävs stor datorkraft, det är uppenbart att stora aktörer på IT-marknaden har tillräckligt med detta. Bland de största företagen som leder utvecklingen inom detta område är Google DeepMind, Microsoft Research, IBM, Facebook och Baidu.
Naturligtvis är allt detta bra: neurala nätverk utvecklas, marknaden växer, men hittills har huvuduppgiften inte lösts. Mänskligheten har misslyckats med att skapa en teknik som till och med ligger nära den mänskliga hjärnans kapacitet. Låt oss ta en titt på de viktigaste skillnaderna mellan den mänskliga hjärnan och artificiella neurala nätverk.
Varför är neurala nätverk fortfarande långt ifrån människans hjärna?
Den viktigaste skillnaden, som i grunden förändrar systemets princip och effektivitet, är den olika signalöverföringen i artificiella neurala nätverk och i det biologiska nätverket av neuroner. Faktum är att i ANN överför neuroner värden som är verkliga värden, det vill säga siffror. I den mänskliga hjärnan överförs impulser med en fast amplitud, och dessa impulser är nästan omedelbara. Därför finns det ett antal fördelar med det mänskliga nätverket av neuroner.
För det första är kommunikationslinjer i hjärnan mycket mer effektiva och ekonomiska än i ANN. För det andra säkerställer impulskretsen enkelheten i teknikimplementeringen: det räcker att använda analoga kretsar istället för komplexa beräkningsmekanismer. I slutändan är impulsenätverk skyddade från akustisk störning. Effektiva siffror utsätts för buller, vilket ökar sannolikheten för fel.
Utsikter för neurala nätverk
Luddite-rörelsen började i början av 1800-talet. Detta ord användes för att beskriva människor som deltar i protester mot urbanisering. Med industrialiseringen av samhället, när verktygsmaskiner gradvis började ersätta arbetare, lämnades många människor utan arbete och var extremt missnöjda med sin situation. Tänk dig vilken chock de skulle ha upplevt om de fick veta att maskinerna om några hundra år kommer att kunna prata och till och med röra sig självständigt!
Under tiden har dessa tider kommit, och idag finns det också retrograder som fruktar att robotik och utveckling av teknik i allmänhet kan spela ett grymt skämt med människor. När allt kommer omkring, om maskiner redan kan utföra så många uppgifter idag, kommer de i framtiden att ta alla jobb och göra människor onödiga. Och denna ståndpunkt bekräftas endast av bedömningar av experter som då och då förutspår det förestående försvinnandet av ett visst yrke.
Denna position har rätt att existera, men den är inte helt korrekt, eftersom över tiden försvinner inte bara gamla yrken utan också nya. Ja, det finns en storleksordning mindre herdar och jägare än tidigare, men programmerare och marknadsförare har dykt upp. Vid vändpunkter i historien omorienterar ekonomin sig själv, rensar bort de onödiga och generöst ger dem som är efterfrågade.
Det växande inflytandet från artificiella neurala nätverk är uppenbart och det är troligt att de snart kommer bokstavligen överallt, men att vara rädd för detta innebär att man avvisar den mänskliga naturen, som består i önskan om upptäckt och prestation.
Skapande av neurala block
Först måste du bestämma vad grundkomponenterna i ett neuralt nätverk – neuroner – är. Neuronen tar inmatade data, utför vissa matematiska operationer med den och matar sedan ut resultatet. En neuron med två ingångar ser ut så här:
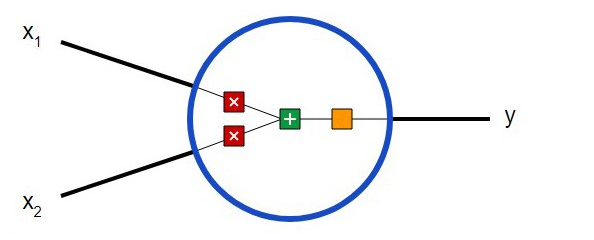
Tre saker händer här. Först multipliceras varje ingång med vikten (i diagrammet är det markerat med rött ):
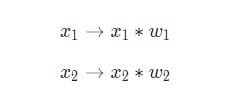
Sedan läggs alla viktade ingångar till tillsammans med förskjutningen b(anges i grönt i diagrammet ):
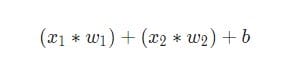
Slutligen överförs beloppet via aktiveringsfunktionen (markerad med gult i diagrammet ):

Aktiveringsfunktionen används för att ansluta orelaterade ingångar till en utgång som har en enkel och förutsägbar form. Som regel tas sigmoidfunktionen som aktiveringsfunktionen som används :
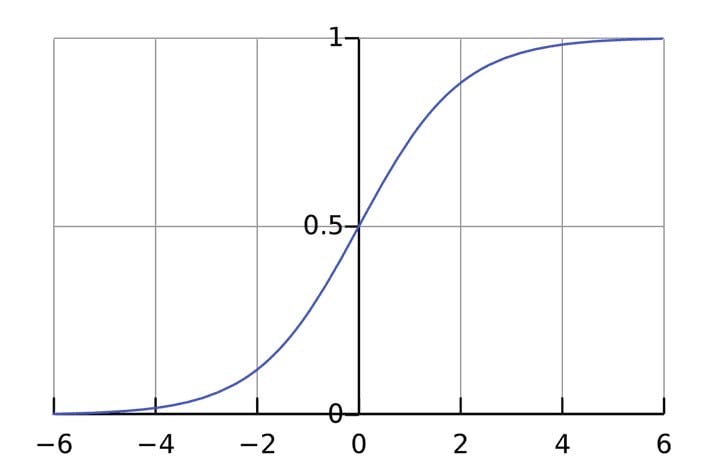
Sigmoid-funktionen matar bara ut siffror i ett intervall (0, 1). Du kan tänka på det som att komprimera från (−∞, +∞)till (0, 1). Stora negativa tal blir ~0, och stora positiva siffror blir ~1.
Ett enkelt exempel på att arbeta med nervceller i Python
Antag att vi har en neuron med två ingångar som använder sigmoid-aktiveringsfunktion och har följande parametrar:
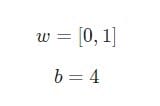
w = [0,1]Är bara ett sätt att skriva w1 = 0, w2 = 1i vektorform. Låt oss tilldela neuron en ingång med ett värde x = [2, 3]. För en mer kompakt representation kommer dot-produkten att användas .
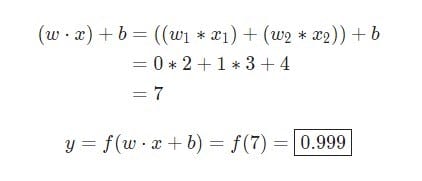
Med tanke på att ingången var x = [2, 3]kommer utgången att vara lika 0.999. Det är allt. Denna process för att skicka indata till mottagning av utdata kallas feedforward.
Bygga en neuron från grunden i Python
Låt oss börja implementera neuronen. Detta kräver användning av NumPy. Det är ett kraftfullt beräknings Python-bibliotek som använder matematiska operationer:
|
ett 2 3 fyra fem 6 7 åtta nio 10 elva 12 13 fjorton femton sexton 17 arton nitton tjugo 21 22 23 24 25 26 27 |
importera numpy som np def sigmoid ( x ) : # Vår aktiveringsfunktion: f (x) = 1 / (1 + e ^ (- x)) returnera 1 / ( 1 + np . exp ( – x ) ) klass Neuron : def __init__ ( själv , vikter , bias ) : själv . vikter = vikter själv . bias = bias def feedforward ( själv , ingångar ) : # Inmatningsviktdata, lägg till offset # och efterföljande användning av aktiveringsfunktionen totalt = np . dot ( själv . vikter , ingångar ) + själv . partiskhet retur sigmoid ( totalt ) vikter = np . array ( [ 0 , 1 ] ) # w1 = 0, w2 = 1 bias = 4 # b = 4 n = Neuron ( vikter , bias ) x = np . array ( [ 2 , 3 ] ) # x1 = 2, x2 = 3 skriva ut ( n . feedforward ( x ) ) # 0.9990889488055994 |
Känner du igen siffrorna? Detta är samma exempel som diskuterats tidigare. Svaret som erhölls denna gång är också lika 0.999.
Ett exempel på att samla neuroner i ett neuralt nätverk
Ett neuralt nätverk är i huvudsak en grupp av sammankopplade nervceller. Ett enkelt neuralt nätverk ser ut så här:
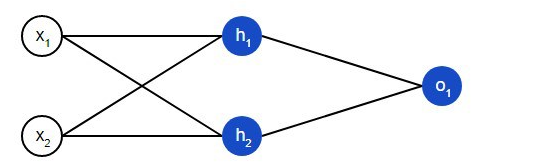
På det inledande skiktet i nätverket finns det två ingångar – x1och x2. Det finns två neutroner på det dolda lagret – h1och h2. Det finns en neuron i utgångsskiktet – о1. Observera att ingångarna för о1är resultat h1och h2. Så här är det neurala nätverket uppbyggt.
Ett dolt lager är vilket skikt som helst mellan ingångsskiktet och utskiktet, vilket är det första respektive det sista lagret. Det kan finnas flera dolda lager.
Neural nätverksutbildning
Utgång ŷ från ett enkelt tvåskiktsneuralt nätverk:
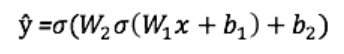
I ovanstående ekvation är vikterna W och förspänningarna b de enda variablerna som påverkar utgången ŷ.
Naturligtvis bestämmer de korrekta värdena för vikterna och förspänningarna förutsägelserna. Processen för finjustering av vikter och förspänningar från inmatad data är känd som neuralt nätverksutbildning.
Varje iteration av träningsprocessen består av följande steg
- beräkning av den förutsagda utgången ŷ kallad framåtutbredning
- uppdatera vikter och fördomar som kallas backpropagation
Den sekventiella grafen nedan illustrerar processen:

Direkt distribution
Som vi såg i diagrammet ovan är framåtutbredning bara en enkel beräkning, och för ett grundläggande 2-skiktsneuralt nätverk ges resultatet från det neurala nätverket av:
Låt oss lägga till flöde till vår Python-kod för att göra detta. Observera att för enkelhetens skull har vi antagit att förskjutningarna är 0.
Vi behöver dock ett sätt att bedöma ”godheten” i våra prognoser, det vill säga hur långt våra prognoser är). Förlustfunktionen gör att vi kan göra just det.
Förlustfunktion
Det finns många förlustfunktioner tillgängliga, och karaktären av vårt problem bör diktera vårt val av förlustfunktion. I denna uppsats kommer vi att använda summan av kvadraten för felen som förlustfunktionen.

Summan av kvadratfel är genomsnittet av skillnaden mellan varje förutsagt värde och det verkliga värdet.
Målet med träningen är att hitta en uppsättning vikter och förspänningar som minimerar förlustfunktionen.
Tillbaka förökning
Nu när vi har mätt vårt prognosfel (förluster) måste vi hitta ett sätt att sprida felet tillbaka och uppdatera våra vikter och fördomar.
För att ta reda på lämplig mängd att korrigera för vikter och förspänningar måste vi känna till förlustfunktionens derivat med avseende på vikter och förspänningar.
Kom ihåg från analysen att derivatet av en funktion är tangenten för funktionens lutning.
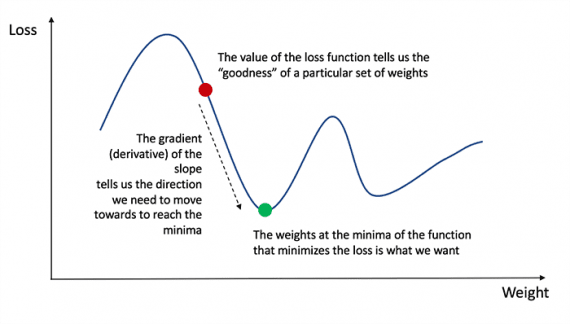
Om vi har ett derivat kan vi helt enkelt uppdatera vikterna och förspänningarna genom att öka / minska dem (se diagram ovan). Detta kallas gradientnedstigning.
Vi kan dock inte direkt beräkna förlustfunktionens derivat med avseende på vikter och förspänningar, eftersom ekvationen för förlustfunktionen inte innehåller vikter och förspänningar. Därför behöver vi en kedjeregel för att underlätta beräkningen.
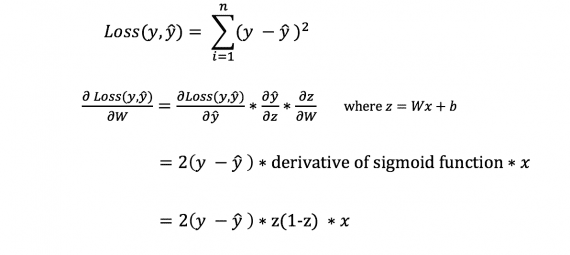
Fuh! Det var besvärligt, men det tillät oss att få vad vi behöver – derivatet (lutningen) av förlustfunktionen med avseende på vikterna. Vi kan nu justera vikterna därefter.
Låt oss lägga till backpropagation-funktionen i vår Python-kod:
Partiella derivat
Delderivat kan beräknas, så det är känt vad som var bidraget till felet för varje vikt. Behovet av derivat är uppenbart. Föreställ dig ett neuralt nätverk som försöker hitta den optimala hastigheten för ett autonomt fordon. Om bilen upptäcker att den går snabbare eller långsammare än den erforderliga hastigheten, kommer neuronnätverket att ändra hastigheten, accelerera eller retardera bilen. Vad accelererar / bromsar samtidigt? Hastighetsderivat.
Låt oss titta på behovet av partiella derivat med hjälp av ett exempel.
Antag att barnen ombeds att kasta en pil på ett mål medan de siktar mot mitten. Här är resultaten:

Nu, om vi hittar ett allmänt fel och helt enkelt subtraherar det från alla vikter, kommer vi att sammanfatta misstag som görs av var och en. Så låt oss säga att barnet träffade för lågt, men vi ber alla barn att sträva efter att träffa målet, då kommer detta att leda till följande bild:
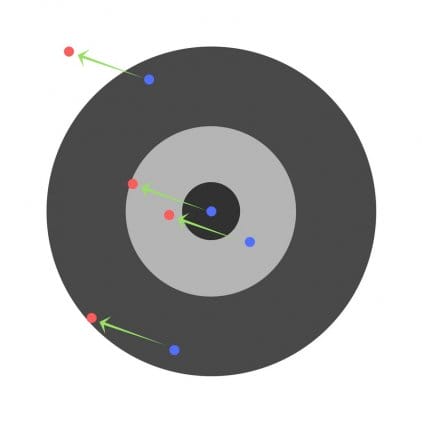
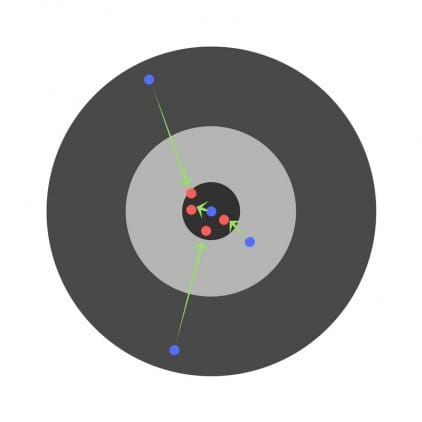
Felet hos flera barn kan minska, men det totala felet ökar fortfarande.
Efter att ha hittat delderivaten får vi reda på de fel som motsvarar varje vikt separat. Om du selektivt korrigerar vikterna kan du få följande:
Hyperparametrar
Ett neuralt nätverk används för att automatisera funktionsval, men vissa parametrar konfigureras manuellt.
Inlärningshastighet
Inlärningshastighet är en mycket viktig hyperparameter. Om inlärningshastigheten är för låg, kommer det att vara långt ifrån optimala resultat även efter att ha tränat neuralt nätverk under lång tid. Resultaten kommer att se ut så här:
Å andra sidan, om inlärningshastigheten är för hög, kommer nätverket att svara mycket snabbt. Resultatet är följande:

Djupa neurala nätverk
Deep learning är en klass av maskininlärningsalgoritmer som lär sig att förstå data djupare (mer abstrakt). Populära algoritmer för djupinlärande neurala nätverk presenteras i diagrammet nedan.
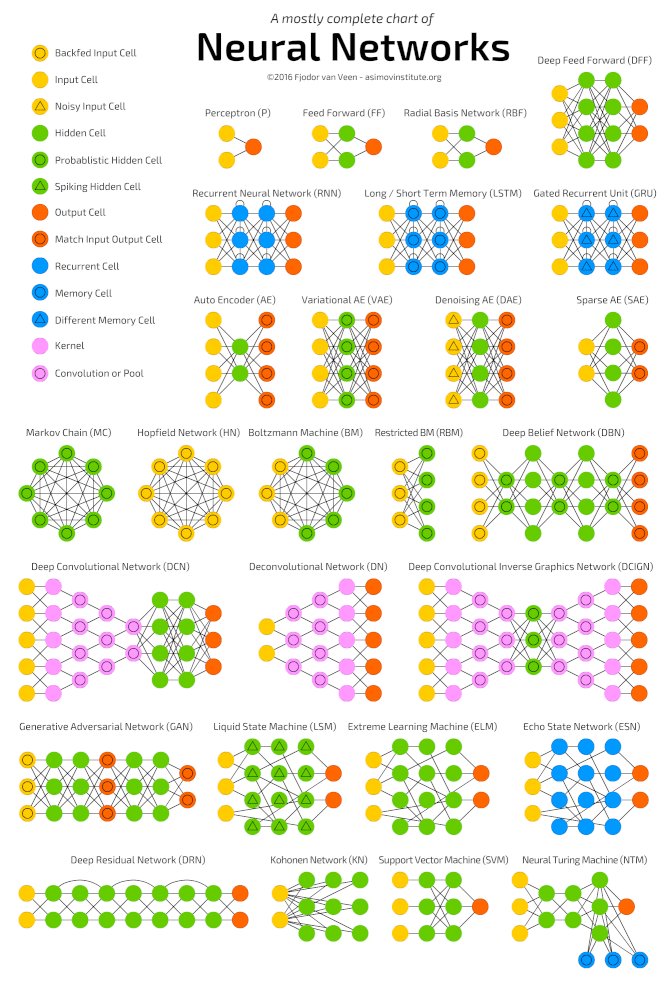
Populära neurala nätverksalgoritmer (http://www.asimovinstitute.org/neural-network-zoo )
Mer formellt i djupinlärning:
- En kaskad (pipeline, som en sekventiellt överförd ström) av ett flertal bearbetningsskikt (icke-linjär) används för att extrahera och transformera funktioner;
- Baserat på studien av funktioner (presentation av information) i data utan övervakat lärande. Funktionerna på högre nivå (som finns i de sista skikten) erhålls från de lägre nivåfunktionerna (som finns i de första skiktens lager);
- Utforskar skiktade vyer som motsvarar olika abstraktionsnivåer; nivåer bildar en presentationshierarki.
Träna det neurala nätverket med XOR-funktioner
Varför är XOR-funktionen så intressant? Helt enkelt för att den inte kan erhållas av en neuron: 0 ^ 0 = 0, 0 ^ 1 = 1, 1 ^ 0 = 1, 1 ^ 1 = 0. Det erhålls dock enkelt genom att öka antalet neuroner. Vi kommer att försöka träna ett nätverk med 3 nervceller i det dolda lagret och en utgång (eftersom vi bara har en utgång). För att göra detta måste vi skapa en uppsättning X- och Y-vektorer med träningsdata och det neurala nätverket:
// массив входных обучающих векторов Vector[] X = { new Vector(0, 0), new Vector(0, 1), new Vector(1, 0), new Vector(1, 1) }; // массив выходных обучающих векторов Vector[] Y = { new Vector(0.0), // 0 ^ 0 = 0 new Vector(1.0), // 0 ^ 1 = 1 new Vector(1.0), // 1 ^ 0 = 1 new Vector(0.0) // 1 ^ 1 = 0 }; Network network = new Network(new int[]{2, 3, 1}); // создаём сеть с двумя входами, тремя нейронами в скрытом слое и одним выходом Sedan börjar vi träna med följande parametrar: inlärningshastighet – 0,5, antal epoker – 100000, felvärde – 1e-7:
network.Train(X, Y, 0.5, 1e-7, 100000); // запускаем обучение сети Efter träning, låt oss titta på resultaten genom att utföra ett direktkort för alla element:
for (int i = 0; i Inspelningskälla: lastici.ru