«How to Lie with Statistics» av Darell Huff. Hvordan lyve med statistikk

Innhold
Prøvetaking bias
I 1948, under presidentløpet i USA på valgkvelden Truman (demokrater) kontra Dewey (republikanere), publiserte Chicago Tribune den kanskje mest berømte overskriften DEWEY DEFEATS TRUMAN (se bildet). Umiddelbart etter stenging av valglokalene gjennomførte avisen en avstemning og kalte et enormt (nok for et utvalg) antall velgere, og alt varslet en rungende seier for Dewey. Bildet viser Truman, vinneren av det 48. valget, ler. Hva gikk galt?
Folk ble ringt ved en tilfeldighet og i tilstrekkelig antall, men i det 48. året var telefonen bare tilgjengelig for personer med en viss inntekt og ble sjelden funnet blant personer med liten inntekt. Dermed innfører valgmålingsmetoden en endring av fordelingen av stemmer. Utvalget tok ikke hensyn til et ganske bredt lag av Trumans velgere (som regel har demokrater en stor andel stemmer blant de fattige), som telefonen i sin tur ikke var tilgjengelig for. Dette valget kalles partisk.
Velg riktig gjennomsnitt (velvalgt gjennomsnitt)
Tenk deg et selskap der en leder mottar 25 tusen, hans stedfortreder mottar 7,6 tusen, toppledere – 5,5 tusen, mellomledere – 3,5 tusen, juniorledere – 2,5 tusen, og vanlige arbeidere – 1, 4 tusen (abstrakte pund) per måned.
Og vår oppgave er å presentere informasjon om selskapet i et positivt lys. Vi kan skrive gjennomsnittlig lønn i selskapet er X, men hva betyr gjennomsnittet? Vurder de mulige alternativene (se diagrammet nedenfor): Det aritmetiske gjennomsnittet av et endelig mengde X = {xi} er et tall m som er gjennomsnittet (X) fra ligningen: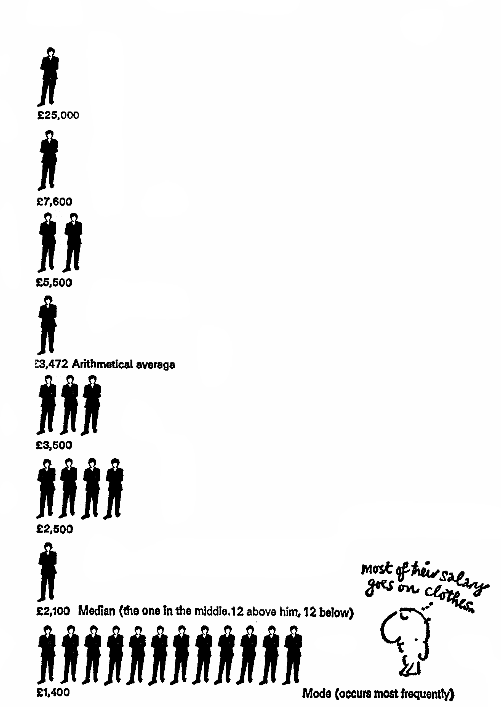
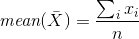
Dette er den mest ubrukelige informasjonen fra en ansattes synspunkt – 3.472 gjennomsnittslønn, men hva gjør så høyt? På grunn av ledelsens høye lønn, noe som skaper en illusjon om at den ansatte vil motta samme beløp. Fra ansattes synspunkt er ikke denne verdien spesielt informativ.
Selvfølgelig gikk ikke folkekunst forbi denne funksjonen av «gjennomsnittsstørrelsen» i form av et aritmetisk middel
Tjenestemenn spiser kjøtt, jeg spiser kål. I gjennomsnitt spiser vi kålruller.
Medianen for noen fordeling P (X) (X = {xi}) er en slik verdi m at den tilfredsstiller følgende ligning: Enkelt sagt, halvparten av arbeiderne får mer enn denne verdien, og halvparten mindre – nøyaktig midten av fordeling! Denne statistikken er ganske informativ for de ansatte i selskapet, da den lar deg bestemme hvordan den ansattes lønn korrelerer med de fleste ansatte. Modusen til et endelig sett X = {xi} er tallet m som forekommer oftest i X. I dette tilfellet kan mote være den mest informative for en person som skal begynne å jobbe i et gitt selskap.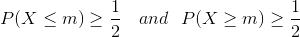
Avhengig av situasjonen kan den gjennomsnittlige verdien således forstås som noen av de ovennevnte verdiene (i prinsippet og ikke bare av dem). Derfor er det grunnleggende viktig å forstå hvordan dette gjennomsnittet beregnes.
Og 10 flere mislykkede eksperimenter som vi ikke har skrevet om
La oss legge en vanlig avis i svovelsyre, og TV Park magazine i destillert vann! Føl forskjellen? Ingenting skjedde med bladet – papiret er som nytt! Våre forskningsrapporter Doakes tannkrem er 23% mer effektiv enn konkurrentene, takket være Dr Cornishs tannpulver! (Som sannsynligvis inneholdt β-karoten og skogens hemmelige formel – forfatterens kommentar.) Du vil kanskje bli overrasket, men forskningen ble faktisk utført og til og med utgitt en teknisk rapport. Og eksperimentet viste at tannkrem er 23% mer effektiv enn konkurrentene (hva det enn betyr). Men er dette bare hele historien?
I virkeligheten var prøven for eksperimentet bare et dusin mennesker (ifølge Darrell Huff og boka som allerede er nevnt). Dette er nøyaktig prøven du trenger for å få noen resultater! La oss si at vi vender en mynt fem ganger. Hva er sannsynligheten for at du vil lande hoder alle fem ganger? (1/2) 5 = 1/32. Bare en trettito, det kan ikke bare være en tilfeldighet at alle fem hodene kommer opp, kan det? La oss forestille oss at vi gjentar dette eksperimentet 50 ganger. Minst ett av disse forsøkene vil lykkes. Vi vil skrive om det i rapporten, og alle andre eksperimenter vil ikke gå noe sted. Dermed vil vi motta utelukkende tilfeldige data som passer perfekt inn i vår oppgave.
Leker med skalaen
Anta at i morgen må du vise på et møte at vi har fått med oss konkurransen, men tallene konvergerer ikke litt, hva skal vi gjøre? La oss flytte skalaen litt! Selv den anerkjente New York Times, kjent for sitt kvalitetsdataarbeid, har gitt ut en helt forvirrende graf som denne (merk hoppet fra 800k til 1,5m i midten av skalaen). (eksempel fra Howard Wainer. Den amerikanske statistikeren, 1984.)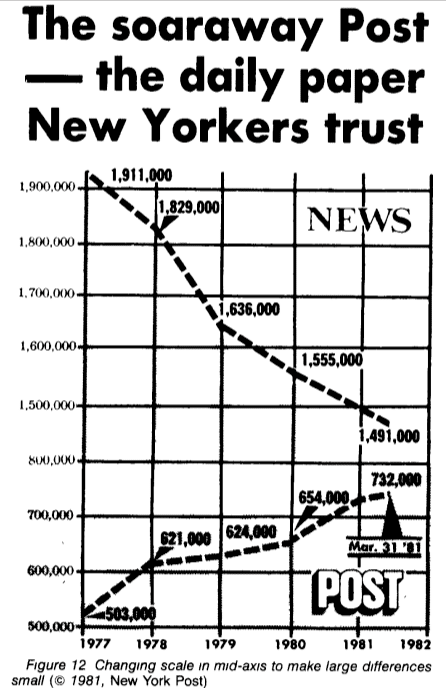
Vi velger 100%
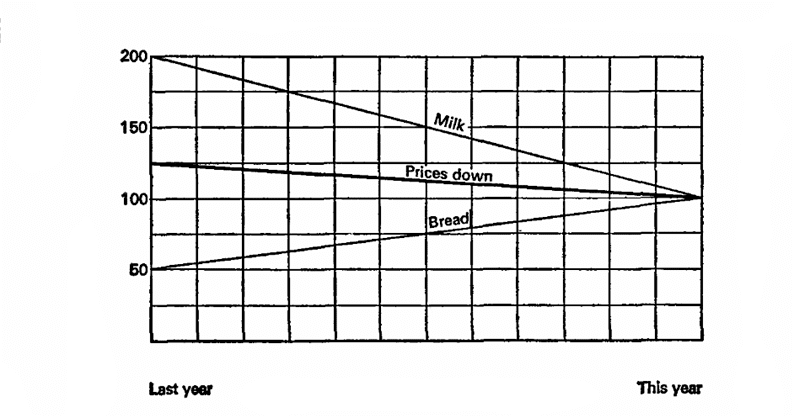
La oss forestille oss at melk i fjor kostet 10 kopekk per liter og brød var 10 kopekk per brød. I år har melk falt i pris med 5 kopekk, og brød har vokst med 20. Oppmerksomhet på spørsmålet, hva vil vi bevise?
La oss forestille oss at fjoråret er 100%, grunnlaget for beregninger. Da falt melk i pris med 50%, og brød økte med 200%, et gjennomsnitt på 125%, noe som betyr at prisene generelt økte med 25%. La oss prøve igjen, la inneværende år være 100%, noe som betyr at melkeprisene var 200% i fjor, og brød 50%. Dette betyr at prisene i fjor i gjennomsnitt var 25% høyere!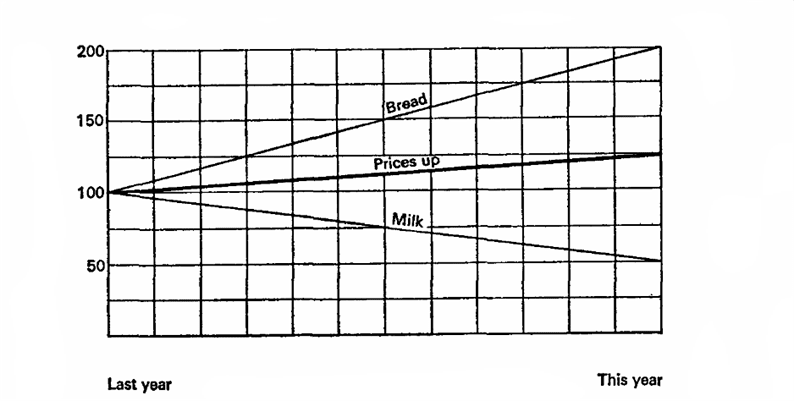
Samle inn dataene som vil gjøre konklusjonene dine enda mer partiske
Det første trinnet i å samle inn statistikk er å bestemme hva du vil analysere. Statistikere kaller informasjon på dette stadiet for befolkningen. Deretter må du definere en underklasse med data som, når de analyseres, skal representere hele befolkningen som helhet. Jo større og mer nøyaktig utvalget, desto mer nøyaktige blir forskningsresultatene.
Det er selvfølgelig forskjellige måter å ødelegge et statistisk utvalg ved et uhell eller med vilje:
- Utvalg bias. Denne feilen oppstår når de som deltar i studien identifiserer seg selv som en gruppe som ikke representerer hele befolkningen.
- Tilfeldig prøvetaking. Oppstår når lett tilgjengelig informasjon blir analysert i stedet for å prøve å samle representative data. For eksempel kan en nyhetskanal gjennomføre en politisk undersøkelse blant seerne. Uten å spørre folk som ser på andre kanaler (eller ikke ser TV i det hele tatt), kan det ikke sies at resultatene av en slik studie vil gjenspeile virkeligheten.
- Avslag fra respondenter på å delta. En slik statistisk feil oppstår når noen ikke svarer på spørsmålene i en statistisk studie. Dette fører til feil resultatvisning. For eksempel, hvis en studie stiller spørsmålet: «Har du noen gang lurt på ektefellen din?» Som et resultat vil det se ut til at juks er sjelden.
- Undersøkelser om gratis tilgang. Alle kan delta i slike undersøkelser. Ofte sjekkes det ikke engang hvor mange ganger den samme personen har svart på spørsmål. Et eksempel er forskjellige undersøkelser på Internett. Det er veldig interessant å passere dem, men de kan ikke betraktes som objektive.
Det fine med valgforstyrrelse er at noen, et eller annet sted, sannsynligvis vil gjennomføre en uvitenskapelig undersøkelse som vil støtte hvilken teori du har. Så det er bare å søke på nettet etter avstemningen du ønsker, eller lage din egen.
Velg resultater som støtter ideene dine
Siden statistikk bruker tall, ser det ut til at de overbevisende beviser enhver ide. Statistikk er avhengig av komplekse matematiske beregninger som, hvis feil behandlet, kan føre til helt motsatte resultater.
For å demonstrere feilene i dataanalysen opprettet den engelske matematikeren Francis Anscombe Anscombe-kvartetten. Den består av fire sett med numeriske data som ser helt annerledes ut på grafene.
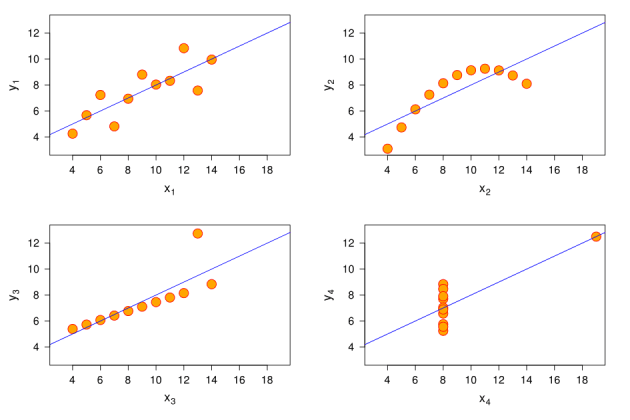
Figur X1 er et standard spredningsdiagram; X2 er en kurve som først stiger opp og deretter faller ned; X3 – en linje som stiger litt oppover, med en overskridelse på Y-aksen; X4 – data på X-aksen, bortsett fra en overskudd plassert høyt på begge akser.
For hver av grafene gjelder følgende utsagn:
- Gjennomsnittet av x for hvert datasett er 9.
- Gjennomsnittet av y for hvert datasett er 7,5.
- Variansen (spredning) av x-variabelen er 11, og y-variabelen er 4,12.
- Korrelasjonen mellom variablene x og y for hvert datasett er 0,816.
Hvis vi bare så disse dataene i form av tekst, ville vi tro at situasjonene er de samme, selv om grafene motbeviser dette.
Derfor foreslo Enscombe at du først visualiserer dataene, og først deretter trekker konklusjoner. Selvfølgelig, hvis du vil villede noen, hopper du over dette trinnet.
Lag grafer som fremhever de ønskede resultatene
De fleste har ikke tid til å gjøre sin egen statistiske analyse. De forventer at du skal vise dem grafer som oppsummerer all din forskning. Godt utformede diagrammer skal gjenspeile ideer som passer til virkeligheten. Men de kan også markere dataene du vil vise.
Utelat navnene på noen parametere, endre skalaen på koordinataksen, ikke forklar sammenhengen. Så du kan overbevise alle om at du har rett.
For all del, skjul kilder
Hvis du åpent siterer kildene dine, er det enkelt for folk å verifisere funnene dine. Hvis du prøver å få alle rundt fingeren, må du selvfølgelig aldri fortelle hvordan du kom til konklusjonene dine.
Vanligvis er referanser til kilder alltid angitt i artikler og studier. Samtidig kan det hende at originale verker ikke blir gitt i sin helhet. Det viktigste er at kilden svarer på følgende spørsmål:
- Hvordan ble dataene samlet inn? Ble folk intervjuet på telefon? Eller ble det stoppet på gaten? Eller var det en Twitter-avstemning? Metoden for å samle informasjon kan indikere visse valgfeil.
- Når møttes de? Forskning blir fort utdatert og trender endres, så tidspunktet for informasjonsinnhenting påvirker konklusjoner.
- Hvem samlet dem? Det er liten troverdighet i tobakksbedriftens forskning om sikkerheten ved røyking.
- Hvem ble intervjuet? Dette er spesielt viktig for meningsmålingene. Hvis en politiker gjennomfører en undersøkelse blant de som sympatiserer med ham, vil ikke resultatene gjenspeile meningen fra hele befolkningen.
Hvordan lyve ved hjelp av statistikk – Del 2
Vi fortsetter å analysere hvordan du kan villede folk ved å bruke statistikk feil. Forrige innlegg
Middels utvalg
Du kan ofte høre ordet «gjennomsnitt» i nyheter og annonser. Men hva er middel? Det er aritmetisk gjennomsnitt, geometrisk middel, harmonisk middel og listen fortsetter! Og upassende valg (ved et uhell eller bevisst) valg av middel kan forvride resultatene betydelig.
La oss se på et eksempel. Anta at vi har tre personer: bestemor Elena Anatolyevna med en pensjon på 8000, systemadministrator Vasya med en lønn på 40.000 og millionær Pavel Umnov, som tjener nøyaktig en million i måneden
Hvis vi bare beregner det aritmetiske gjennomsnittet ved å legge til lønnene deres og dele med 3, får vi at det er lik 350 tusen rubler! Det gjenstår å behage bestemor med disse nyhetene
På en logaritmisk skala ser disse verdiene ikke engang for langt fra hverandre. Rød linje – aritmetisk gjennomsnitt
For slike tilfeller er et middel som medianen bedre egnet. Dette er verdien som deler alle våre data i to like store deler (etter mengde). Medianverdien for dette eksemplet vil være lønnen til systemadministratoren Vasya – 40 000. Før og etter henne er det like mange mennesker (en om gangen). Da kunne vi kalle Vasya en person med en gjennomsnittslønn, alle som mottar mindre enn Vasya – med en liten inntekt, mer – rike.
Ved hjelp av medianen ville det tvert imot være mulig å skjule veldig fremtredende (opp eller ned) verdier
Folding ikke-folding
Tenk på klassifiseringssystemet med fem poeng i skolen. Tenk deg at en 7. klassing Danil skrev en diktat for 5, og klassekameraten Leonardo bestemte seg for å skrive den fra høyre til venstre og mottok en to. Vi deler 5 med 2 og vi får at Danil skrev diktatet 2,5 ganger bedre! Ikke sant?
Feil. Poeng er en konstruert nominell variabel som numerisk uttrykker verbale karakterer av gode, gode og så videre. Er «utilfredsstillende» nøyaktig 2,5 ganger verre enn «utmerket»?
Derfor er det ikke matematisk meningsfylt å beregne gjennomsnittspoeng for karakterer eller for noen tester.
Forutinntatt prøvetaking
I følge data om stemmegivning på internett bruker 100% av mennesker Internett
Før noen statistikk kan du lyve hvis du samler inn dataene feil. Et klassisk eksempel er det amerikanske presidentløpet i 1948: Dewey vs. Truman. Chicago Tribune gjennomførte en avstemning umiddelbart etter at valglokalene ble stengt, og ringte til et stort antall mennesker. Og ifølge resultatene, og forutsi en rungende suksess, ga Dewey ut en avis med overskriften » DEWEY Wins Truman .» Bildet viser en lattermild Truman, vinner av 1948-valget, med akkurat denne avisen i hendene
Noe gikk galt? Avisen ringte et tilstrekkelig antall velgere for utvalget, og faktisk tilfeldige. Bare tilnærmingen i seg selv var feil – telefonen på den tiden var ikke tilgjengelig for den fattige befolkningen, hvorav hovedparten var Trumans støtte.
Et annet eksempel er lønn til kandidater som er lovet av universitetene. I USA gikk det til og med for domstolene – kandidater hevdet at lønnsdataene ble kunstig oppblåst. Men poenget er helt annerledes: det er bare det at bare folk som er fornøyde med dem, deler data om inntektene sine med universitetet.
«Visuell» visualisering
Det er tusen og en måte å pynte på dataene på. Visualiser dem for eksempel visuelt. Det kan hjelpe å lese kjedelige diagrammer, og hvis det er gjort med litt lureri, er det mer lønnsomt å presentere dem.
Her er en graf over amerikansk ølforbruk i millioner fat og Schlitzs andel. Han er virkelig imponerende!
Men la oss sette denne grafen i en strengere form: vis dataene med prikker og start y-aksen fra null:
Virker ikke så imponerende lenger. Når man plotter punkter på grafen i form av tønner, oppfatter folk visuelt ikke toppen av tønnene, men volumet. Og når siden av fatet forstørres med 2 ganger, øker volumet med 8 ganger! På en slik skala hjelper y-aksen fra 100.
Her er et annet eksempel. Fantastiske infografikker som viser hvor mye penger som brukes på å bekjempe sykdommer og dødsfall fra dem
Ideen er flott. Ta imidlertid en nærmere titt på tallene. Prisen med en oransje sirkel er omtrent 2 ganger mindre enn med en rosa. Men den rosa sirkelen er 4 ganger større!
Forfatterne foretrakk å gjøre sirkelens radius avhengig av prisen. Men vi oppfatter visuelt ikke radiusen i det hele tatt, men figurens område! Og formelen for sirkelområdet avhenger av radiusen kvadratisk
Denne infografikken kan gjøres enda bedre ved å plassere de samme sykdommene på samme linje. Slik ser den reviderte versjonen ut:
Visualisering er ikke bare mer troverdig, men gir også ideen: noen sykdommer er ikke så farlige som penger blir brukt på dem, og kampen mot andre er underfinansiert.
Et eksempel på høykvalitets visualisering
Grafen viser størrelsen på Napoleons hær. Det ekstreme høyre punktet er Moskva, hvorfra retretten begynner, vist med en svart stripe. Tid og temperatur grafen er også knyttet til retrettplanen. Svært tydelig!
Om boka «How to Lie Using Statistics» av Darell Huff
I denne verdensberømte boken diskuterer Darell Huff de forskjellige måtene statistikk misbrukes for å lure og manipulere publikum. Hver dag prøver de å påvirke deg for å oppmuntre deg til å kjøpe noe «nødvendig» produkt eller velge «riktig» kandidat: «Takket være» Clean Teeth «lim reduseres dannelsen av karies med 23%!»; «N-politikken støttes av 85% av innbyggerne» … Hvordan forstå hvor pålitelige visse data er? Hvordan er beregningene? Hva blir tatt i betraktning og hva som gjenstår bak kulissene? Forfatteren avslører statistikernes hemmelige verktøy og utstyr leseren med kunnskap som vil bidra til å forstå alle komplikasjonene i denne vitenskapen og som ikke tillater forvirring.
kommentar
I denne verdensberømte boken diskuterer Darell Huff de forskjellige måtene statistikk misbrukes for å lure og manipulere publikum. Hver dag prøver de å påvirke deg for å oppmuntre deg til å kjøpe noe «nødvendig» produkt eller velge «riktig» kandidat: «Takket være» Clean Teeth «lim reduseres kariesdannelsen med 23%!»; «N-policy støttes av 85% av innbyggerne» … Hvordan forstå hvor pålitelige disse eller de dataene er? Hvordan gjøres beregningen? Hva blir tatt i betraktning og hva blir igjen bak kulissene? Forfatteren avslører de hemmelige verktøyene til statistikere og utstyrer leseren med kunnskap som vil bidra til å forstå alle komplikasjonene i denne vitenskapen og som ikke lar deg bli villedet.
Kilder som brukes og nyttige lenker om emnet: https://habr.com/ru/post/217545/ https://Lifehacker.ru/4-sposoba-lgat-pri-pomoshhi-statistiki/ https://pikabu.ru / story / kaklgat_s_pomoshchyu_statistiki_chast_2_6113007 https://lifeinbooks.net/chto-pochitat/kak-lgat-pri-pomoshhi-statistiki-darell-haff/ https://coollib.net/b/331961-kat-plgat-
Opptakskilde: lastici.ru