”How to Lie with Statistics” av Darell Huff. Hur man ligger med statistik

Innehåll
Provtagningsförspänning
1948, under presidentloppet i USA på valnatten Truman (demokrater) kontra Dewey (republikaner), publicerade Chicago Tribune kanske sin mest kända rubrik, DEWEY DEFEATS TRUMAN (se foto). Omedelbart efter stängningen av röstlokalerna genomförde tidningen en omröstning och kallade ett enormt (tillräckligt för ett urval) antal väljare, och alla förkunnar en rungande seger för Dewey. Bilden visar Truman, vinnaren av det 48: e valet, skrattar. Vad gick fel?
Människor ringde av en slump och i tillräckligt antal, men det 48: e året var telefonen endast tillgänglig för personer med en viss inkomst och hittades sällan bland personer med liten inkomst. Således inför själva valmetoden en ändring av röstfördelningen. Urvalet tog inte hänsyn till ett ganska brett skikt av Trumans väljare (som regel har demokraterna en stor röstandel bland de fattiga), för vilka telefonen i sin tur inte var tillgänglig. Detta val kallas partisk.
Välja rätt genomsnitt (väl valt medel)
Föreställ dig ett företag där en chef får 25 tusen, hans suppleant får 7,6 tusen, toppchefer – 5,5 tusen, mellanledare – 3,5 tusen, juniorchefer – 2,5 tusen, och vanliga arbetare – 1, 4 tusen (abstrakt pund) per månad.
Och vår uppgift är att presentera information om företaget i ett positivt ljus. Vi kan skriva den genomsnittliga lönen i företaget är X, men vad betyder genomsnittet? Tänk på de möjliga alternativen (se diagrammet nedan): Det aritmetiska medelvärdet för någon ändlig uppsättning X = {xi} är ett tal m lika med medelvärdet (X) från ekvationen: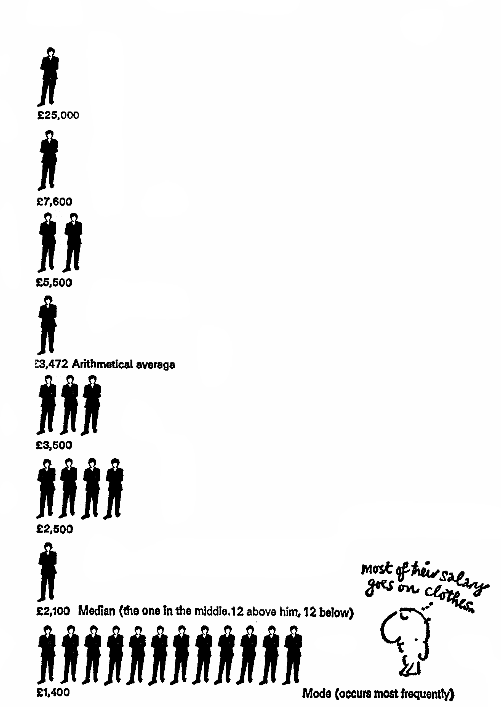
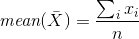
Detta är den mest värdelösa informationen från en anställds synvinkel – 3.472 genomsnittliga löner, men vad gör en så hög siffra? På grund av ledningens höga löner, vilket skapar en illusion om att den anställde kommer att få samma belopp. Ur anställdens synvinkel är detta värde inte särskilt informativt.
Naturligtvis kringgick folkkonsten inte denna egenskap av ”medelstorlek” i form av ett aritmetiskt medelvärde
Tjänstemän äter kött, jag äter kål. I genomsnitt äter vi kålrullar.
Medianen för en viss fördelning P (X) (X = {xi}) är ett sådant värde m att det uppfyller följande ekvation: Enkelt uttryckt, hälften av arbetarna får mer än detta värde och hälften mindre – exakt mitten av distribution! Denna statistik är ganska informativ för företagets anställda, eftersom den gör det möjligt att avgöra hur arbetstagarens lön är relaterad till majoriteten av de anställda. Läget för en ändlig uppsättning X = {xi} är det antal m som förekommer oftast i X. I det här fallet kan mode vara det mest informativa för en person som ska börja arbeta i ett visst företag.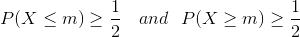
Beroende på situationen kan medelvärdet således förstås som något av ovanstående värden (i princip och inte bara av dem). Därför är det grundläggande viktigt att förstå hur detta genomsnitt beräknas.
Och ytterligare 10 misslyckade experiment som vi inte har skrivit om
Låt oss lägga en vanlig tidning i svavelsyra och TV Park-tidningen i destillerat vatten! Känn skillnaden? Ingenting hände med tidningen – tidningen är som ny! Våra forskningsrapporter Doakes tandkräm är 23% effektivare än tävlingen, tack vare Dr Cornishs tandpulver! (Som förmodligen innehöll β-karoten och skogens hemliga formel – författarens anteckning.) Du kanske blir förvånad, men forskningen genomfördes faktiskt och till och med släppte en teknisk rapport. Och experimentet visade att tandkräm är 23% effektivare än konkurrenterna (vad det än betyder). Men är det bara hela historien?
I själva verket var provet för experimentet bara ett dussin människor (enligt Darrell Huff och boken som redan nämnts). Detta är exakt det prov du behöver för att få några resultat! Låt oss säga att vi vänder ett mynt fem gånger. Vad är sannolikheten att det kommer att landa huvuden alla fem gånger? (1/2) 5 = 1/32. Bara en trettiotvå, det kan inte bara vara en tillfällighet att alla fem huvuden kommer upp, eller hur? Låt oss nu föreställa oss att vi upprepar detta experiment 50 gånger. Åtminstone ett av dessa försök kommer att lyckas. Vi kommer att skriva om det i rapporten, och alla andra experiment kommer inte att gå någonstans. Således får vi uteslutande slumpmässiga data som passar perfekt in i vår uppgift.
Leker med skalan
Antag att du i morgon måste visa på ett möte att vi har kommit i tävlingen, men siffrorna konvergerar inte lite, vad ska vi göra? Låt oss flytta skalan lite! Till och med den berömda New York Times, känd för sitt kvalitetsdataarbete, har släppt en helt förvirrande graf som denna (notera hoppet från 800k till 1,5m i mitten av skalan). (exempel från Howard Wainer. Den amerikanska statistikern, 1984.)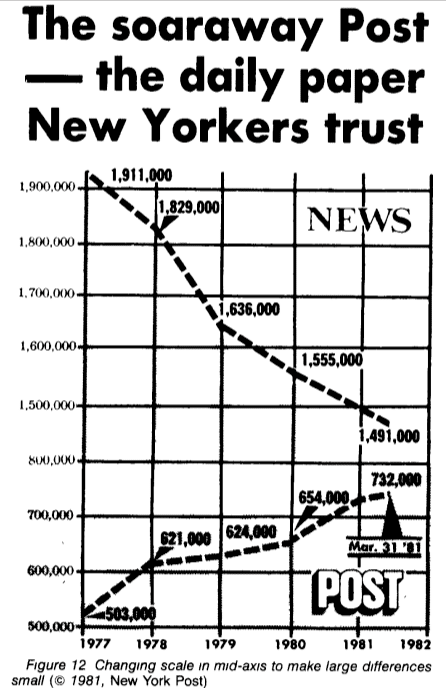
Vi väljer 100%
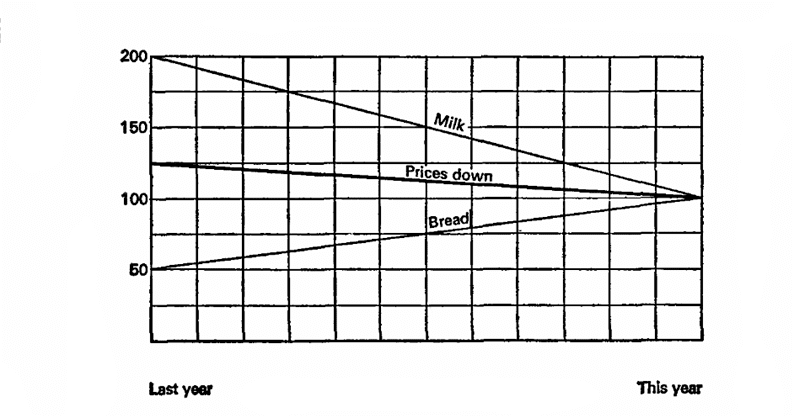
Låt oss föreställa oss att förra året mjölk kostade 10 kopeck per liter och bröd var 10 kopeck per limpa. I år har mjölk sjunkit i pris med 5 kopeck, och bröd har ökat med 20. Uppmärksamhet på frågan, vad vill vi bevisa?
Låt oss föreställa oss att förra året är 100%, grunden för beräkningar. Då sjönk mjölken i pris med 50% och brödet ökade med 200%, i genomsnitt 125%, vilket innebär att priserna i allmänhet ökade med 25%. Låt oss försöka igen, låt det aktuella året vara 100%, vilket innebär att mjölkpriserna var 200% förra året och brödet 50%. Det betyder att priserna förra året i genomsnitt var 25% högre!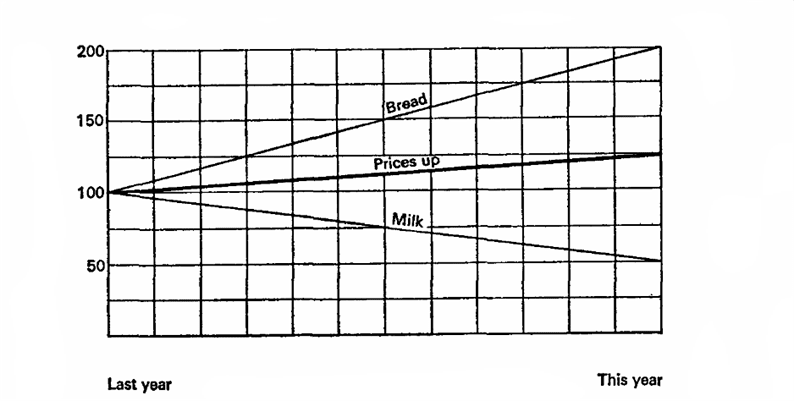
Samla in data som gör dina slutsatser ännu mer partiska
Det första steget i att samla in statistik är att bestämma vad du vill analysera. Statistiker kallar information i detta skede för befolkningen. Därefter måste du definiera en underklass med data som, när de analyseras, ska representera hela befolkningen som helhet. Ju större och mer exakt provet, desto mer exakt blir forskningsresultaten.
Naturligtvis finns det olika sätt att förstöra ett statistiskt urval av misstag eller avsiktligt:
- Urvalsbias. Detta fel inträffar när de personer som deltar i studien identifierar sig som en grupp som inte representerar hela befolkningen.
- Slumpmässigt urval. Uppstår när lätt tillgänglig information analyseras snarare än att försöka samla in representativa data. Till exempel kan en nyhetskanal genomföra en politisk undersökning bland sina tittare. Utan att fråga människor som tittar på andra kanaler (eller inte tittar på TV alls) kan man inte säga att resultaten av en sådan studie kommer att återspegla verkligheten.
- Avslag från respondenter att delta. Ett sådant statistiskt fel inträffar när vissa människor inte svarar på frågorna i en statistisk studie. Detta leder till felaktig visning av resultat. Om en studie till exempel ställer frågan ”Har du någonsin fuskat med din make?” Som ett resultat verkar det som om fusk är sällsynt.
- Undersökningar om fri tillgång. Vem som helst kan delta i sådana undersökningar. Ofta kontrolleras inte ens hur många gånger samma person har svarat på frågor. Ett exempel är olika undersökningar på Internet. Det är väldigt intressant att skicka dem, men de kan inte betraktas som objektiva.
Skönheten i urvalsbias är att någon, någonstans, sannolikt kommer att genomföra en ovetenskaplig undersökning som kommer att stödja vilken teori du har. Så sök bara på webben efter den omröstning du vill ha, eller skapa din egen.
Välj resultat som stöder dina idéer
Eftersom statistik använder siffror verkar det för oss att de på ett övertygande sätt bevisar någon idé. Statistik bygger på komplexa matematiska beräkningar som, om de hanteras felaktigt, kan leda till helt motsatta resultat.
För att visa bristerna i dataanalysen skapade den engelska matematikern Francis Anscombe Anscombe-kvartetten. Den består av fyra uppsättningar numeriska data som ser helt annorlunda ut i graferna.
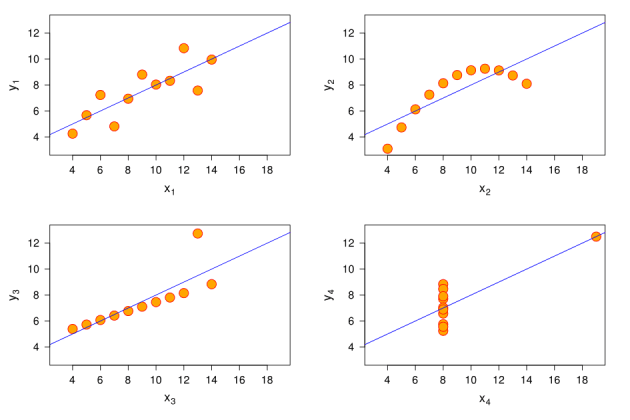
Figur X1 är ett standardspridningsdiagram; X2 är en kurva som först stiger upp och sedan faller ner; X3 – en linje som stiger något uppåt, med en överskjutning på Y-axeln; X4 – data på X-axeln, förutom en avvikare som ligger högt på båda axlarna.
För var och en av graferna gäller följande påståenden:
- Medelvärdet för x för varje dataset är 9.
- Medelvärdet för y för varje dataset är 7,5.
- Variansen (scatter) för x-variabeln är 11 och y-variabeln är 4,12.
- Korrelationen mellan variablerna x och y för varje dataset är 0,816.
Om vi bara såg dessa uppgifter i form av text skulle vi tro att situationerna är helt desamma, även om graferna motbevisar detta.
Därför föreslog Enscombe att du först visualiserar data och endast sedan drar slutsatser. Naturligtvis, om du vill vilseleda någon, hoppa över det här steget.
Skapa diagram som markerar dina önskade resultat
De flesta har inte tid att göra sin egen statistiska analys. De förväntar sig att du visar dem diagram som sammanfattar all din forskning. Väl utformade diagram bör återspegla idéer som passar verkligheten. Men de kan också markera de data du vill visa.
Utelämna namnen på vissa parametrar, ändra skalan något på koordinataxeln, förklara inte sammanhanget. Så du kan övertyga alla om att du har rätt.
Dölj källor
Om du öppet citerar dina källor är det lätt för människor att verifiera dina resultat. Naturligtvis, om du försöker få alla runt fingret, berätta aldrig hur du kom till dina slutsatser.
Vanligtvis anges i artiklar och studier alltid referenser till källor. Samtidigt kanske originalverk inte tillhandahålls i sin helhet. Det viktigaste är att källan svarar på följande frågor:
- Hur samlades data in? Intervjuades människor via telefon? Eller stoppades det på gatan? Eller var det en Twitter-omröstning? Metoden för att samla in information kan indikera vissa urvalsfel.
- När träffades de? Forskning blir snabbt föråldrad och trender förändras, så tidpunkten för informationsinsamling påverkar slutsatser.
- Vem samlade dem? Det finns liten trovärdighet i tobaksföretagets forskning om rökningens säkerhet.
- Vem intervjuades? Detta är särskilt viktigt för opinionsundersökningar. Om en politiker genomför en undersökning bland dem som sympatiserar med honom, återspeglar resultaten inte hela befolkningens åsikt.
Hur man ljuger med hjälp av statistik – Del 2
Vi fortsätter att analysera hur du kan vilseleda människor genom att använda statistik felaktigt. Tidigare inlägg
Medium urval
Du kan ofta höra ordet ”genomsnitt” i nyheter och annonser. Men vad är medelvärdet? Det finns aritmetiskt medelvärde, geometriskt medelvärde, harmoniskt medelvärde och listan fortsätter! Och olämpligt (av misstag eller medvetet) val av medelvärde kan avsevärt snedvrida resultaten.
Låt oss överväga ett exempel. Anta att vi har tre personer: mormor Elena Anatolyevna med en pension på 8000, systemadministratör Vasya med en lön på 40.000 och miljonär Pavel Umnov, som tjänar exakt en miljon i månaden
Om vi bara beräknar det aritmetiska medelvärdet genom att lägga till deras löner och dela med 3 får vi att det är lika med 350 tusen rubel! Det återstår att behaga mormor med den här nyheten
I logaritmisk skala ser dessa värden inte ens för långt ifrån varandra. Röd linje – aritmetiskt medelvärde
För sådana fall är ett medel som medianen bättre lämpad. Detta är värdet som delar upp alla våra data i två lika stora delar (i kvantitet). Medianvärdet för detta exempel är lönen till systemadministratören Vasya – 40 000. Före och efter henne finns samma antal personer (en i taget). Då kunde vi kalla Vasya en person med en genomsnittlig lön, alla som får mindre än Vasya – med en liten inkomst, mer – rika.
Med hjälp av medianen skulle det tvärtom vara möjligt att dölja mycket framträdande (upp eller ner) värden
Hopfällbar, icke-vikbar
Tänk på skolans klassificeringssystem med fem poäng. Tänk dig att en sjunde klass Danil skrev en diktat för 5, och hans klasskamrat Leonardo bestämde sig för att skriva det från höger till vänster och fick ett två. Vi delar 5 med 2 och vi får att Danil skrev dikteringen 2,5 gånger bättre! Rätt?
Fel. Poäng är en konstruerad nominell variabel som numeriskt uttrycker verbala betyg av utmärkta, bra och så vidare. Är ”otillfredsställande” exakt 2,5 gånger värre än ”utmärkt”?
Således är det inte matematiskt meningsfullt att beräkna medelvärden för betyg eller för några tester.
Partisk provtagning
Enligt omröstningsdata på Internet använder 100% av Internet internet
Innan någon statistik kan du ljuga om du samlar in uppgifterna felaktigt. Ett klassiskt exempel är USA: s presidentlopp 1948: Dewey vs. Truman. Chicago Tribune genomförde en omröstning omedelbart efter att röstlokalerna stängdes och kallade ett stort antal människor. Och enligt resultaten som förutsade en rungande framgång publicerade Dewey en tidning med rubriken ” DEWEY Wins Truman .” Bilden visar en skrattande Truman, vinnare av valet 1948, med just denna tidning i sina händer
Något gick fel? Tidningen ringde ett tillräckligt antal väljare för urvalet, och faktiskt slumpmässiga. Endast själva metoden var fel – telefonen vid den tiden var inte tillgänglig för den fattiga befolkningen, varav huvuddelen var Trumans stöd.
Ett annat exempel är lönerna för akademiker som utlovats av universitet. I USA gick det till och med till domstol – akademiker hävdade att löneuppgifterna var konstgjorda höga. Men poängen är helt annorlunda: det är bara att bara människor som är nöjda med dem delar uppgifter om sina inkomster med universitetet.
”Visuell” visualisering
Det finns tusen och ett sätt att försköna uppgifterna. Visualisera dem till exempel visuellt. Det kan hjälpa till att läsa tråkiga diagram, och om det görs med lite knep är det mer lönsamt att presentera dem.
Här är en graf över amerikansk ölkonsumtion i miljoner fat och Schlitzs andel. Han är verkligen imponerande!
Men låt oss sätta den här grafen i en mer rigorös form: visa data med punkter och starta y-axeln från noll:
Verkar inte så imponerande längre. När man plottar punkter på diagrammet i form av fat, uppfattar människor visuellt inte topparna på faten utan deras volym. Och när sidan på pipan ökas med 2 gånger, ökar volymen med 8 gånger! På denna skala hjälper y-axeln som börjar vid 100.
Här är ett annat exempel. Underbara infografik som visar hur mycket pengar som spenderas på kampen mot sjukdomar och dödsfall av dem
Idén är jättebra. Se dock siffrorna närmare. Priset med en orange cirkel är ungefär 2 gånger mindre än med en rosa. Men den rosa cirkeln är fyra gånger större!
Författarna föredrog att göra cirkelns radie beroende av priset. Men vi uppfattar visuellt inte radien alls utan figurens område! Och formeln för en cirkels area beror på radien kvadratiskt
Denna infografik kan göras ännu bättre genom att placera samma sjukdomar på samma linje. Så här ser den reviderade versionen ut:
Visualisering är inte bara mer trovärdig, utan förmedlar också tydligt tanken: vissa sjukdomar är inte lika farliga som pengar spenderas på dem, och kampen mot andra är underfinansierad.
Ett exempel på visualisering av hög kvalitet
Grafen visar storleken på Napoleons armé. Den yttersta högra punkten är Moskva, från vilken reträtten börjar, visad med en svart rand. Tid- och temperaturdiagrammet är också kopplat till reträttschemat. Väldigt klart!
Om boken ”How to Lie Using Statistics” av Darell Huff
I denna världsberömda bok diskuterar Darell Huff de olika sätten som statistik missbrukas för att lura och manipulera publiken. Varje dag försöker de påverka dig för att uppmuntra dig att köpa en ”nödvändig” produkt eller välja ”rätt” kandidat: ”Tack vare” Clean Teeth ”-pasta minskar bildandet av karies med 23%!”; ”N-politik stöds av 85% av medborgarna” … Hur förstå hur tillförlitliga vissa uppgifter är? Hur är beräkningarna? Vad tas med i beräkningen och vad finns kvar bakom kulisserna? Författaren avslöjar statistikernas hemliga verktyg och utrustar läsaren med kunskap som hjälper till att förstå alla vetenskapens kompliceringar och som inte tillåter förvirring.
anteckning
I denna världsberömda bok diskuterar Darell Huff de olika sätten statistik missbrukas för att lura och manipulera publiken. Varje dag försöker de påverka dig för att uppmuntra dig att köpa någon ”nödvändig” produkt eller välja ”rätt” kandidat: ”Tack vare pastan” Clean Teeth ”minskar kariesbildning med 23%!”; ”N-policy stöds av 85% av medborgarna” … Hur förstå hur pålitlig den här eller den informationen är? Hur görs beräkningen? Vad tas hänsyn till och vad finns kvar bakom kulisserna? Författaren avslöjar statistikernas hemliga verktyg och utrustar läsaren med kunskap som hjälper till att förstå alla vetenskapens krångligheter och inte låter dig vilseleds.
Källor som används och användbara länkar om ämnet: https://habr.com/ru/post/217545/ https://Lifehacker.ru/4-sposoba-lgat-pri-pomoshhi-statistiki/ https://pikabu.ru / story / kaklgat_s_pomoshchyu_statistiki_chast_2_6113007 https://lifeinbooks.net/chto-pochitat/kak-lgat-pri-pomoshhi-statistiki-darell-haff/ https://coollib.net/b/331961-kat-plgat-
Inspelningskälla: lastici.ru