Darell Huffin ”Kuinka valehdella tilastojen kanssa”. Kuinka valehdella tilastojen kanssa

Sisältö
Näytteenoton puolueellisuus
Vuonna 1948, presidentin kilpailun aikana Yhdysvalloissa vaalien iltana Truman (demokraatit) vastaan Dewey (republikaanit), Chicago Tribune julkaisi ehkä tunnetuimman otsikkonsa DEWEY DEFEATS TRUMAN (katso kuva). Heti äänestyspaikkojen sulkemisen jälkeen sanomalehti suoritti kyselyn, jossa kutsuttiin valtava määrä (tarpeeksi otosta varten) äänestäjiä, ja kaikki ilmoitti Deweyn räikeän voiton. Kuvassa Truman, 48. vaalien voittaja, nauraa. Mikä meni vikaan?
Ihmisille soitettiin sattumalta ja riittävästi, mutta 48. vuonna puhelin oli vain tiettyjen tulojen omaavien ihmisten käytettävissä, ja sitä löydettiin harvoin pienituloisten joukosta. Näin ollen äänestysmenetelmä itsessään tuo mukanaan muutoksen äänten jakautumiseen. Otoksessa ei otettu huomioon melko laajaa Trumanin äänestäjien joukkoa (demokraateilla on pääsääntöisesti suuri osuus äänistä köyhien keskuudessa), joille puhelin puolestaan ei ollut käytettävissä. Tätä valintaa kutsutaan puolueelliseksi.
Valitse oikea keskiarvo (hyvin valittu keskiarvo)
Kuvittele yritys, jossa johtaja vastaanottaa 25 tuhatta, hänen sijaisensa 7,6 tuhatta, ylimmän johdon – 5,5 tuhatta, keskijohdon – 3,5 tuhatta, ylimmän johdon – 2,5 tuhatta ja tavallisten työntekijöiden – 1,4 tuhatta (abstraktia puntaa) kuukaudessa.
Ja meidän tehtävämme on esittää tietoa yrityksestä positiivisessa valossa. Voimme kirjoittaa, että yrityksen keskipalkka on X, mutta mitä keskimääräinen tarkoittaa? Harkitse mahdollisia vaihtoehtoja (katso alla oleva kaavio): Joidenkin äärellisten joukkojen aritmeettinen keskiarvo X = {xi} on luku m, joka on yhtälön keskiarvo (X):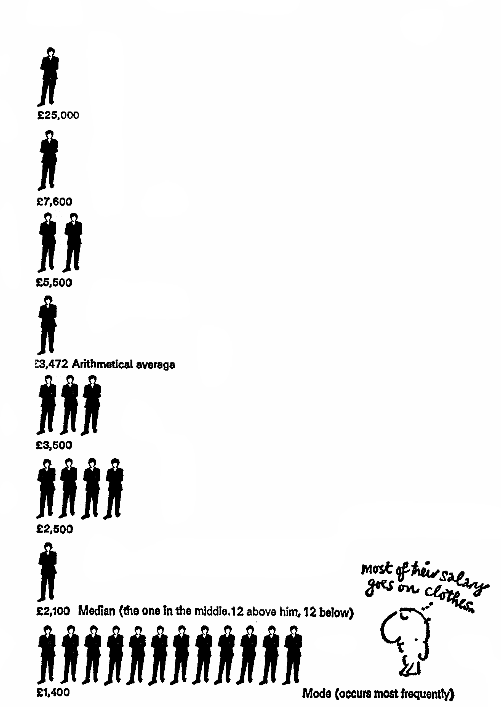
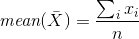
Tämä on työntekijän kannalta hyödyttömin tieto – 3 372 keskipalkkaa, mutta mikä tekee siitä niin korkean luvun? Johdon korkeiden palkkojen takia, mikä luo illuusion siitä, että työntekijä saa saman määrän. Työntekijän kannalta tämä arvo ei ole erityisen informatiivinen.
Tietysti kansantaide ei ohittanut tätä ”keskikoon” ominaisuutta aritmeettisen keskiarvon muodossa
Virkamiehet syövät lihaa, minä kaalia. Keskimäärin syömme kaalirullia.
Jonkin jakauman mediaani P (X) (X = {xi}) on sellainen arvo m, että se täyttää seuraavan yhtälön: Yksinkertaisesti sanottuna puolet työntekijöistä saa enemmän kuin tämä arvo ja puolet vähemmän – täsmälleen jakelu! Nämä tilastotiedot ovat varsin informatiivisia yrityksen työntekijöille, koska niiden avulla voit määrittää, kuinka työntekijän palkka korreloi suurimman osan työntekijöistä. Äärellisen joukon tila X = {xi} on luku m, joka esiintyy useimmin X: ssä. Tässä tapauksessa muoti voi olla kaikkein informatiivisinta henkilölle, joka aikoo aloittaa työskentelyn tietyssä yrityksessä.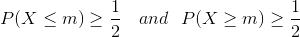
Täten tilanteen mukaan keskiarvo voidaan ymmärtää millä tahansa yllä olevista arvoista (periaatteessa eikä vain niistä). Siksi on pohjimmiltaan tärkeää ymmärtää, kuinka tämä keskiarvo lasketaan.
Ja vielä 10 epäonnistunutta kokeilua, joista emme ole kirjoittaneet
Laitetaan tavallinen sanomalehti rikkihappoon ja TV Park -lehti tislattuun veteen! Tunne erilaisuus? Lehdelle ei tapahtunut mitään – lehti on kuin uusi! Tutkimusraporttimme Doaken hammastahna on 23% tehokkaampi kuin kilpailu, tohtori Cornishin hammastahnan ansiosta! (Joka todennäköisesti sisälsi β-karoteenia ja metsän salaisen kaavan – kirjoittajan huomautus.) Saatat olla yllättynyt, mutta tutkimus toteutettiin ja jopa julkaistiin tekninen raportti. Ja kokeilu osoitti, että hammastahna on 23% tehokkaampi kuin kilpailu (mitä se tarkoittaa). Mutta onko tämä vain koko tarina?
Todellisuudessa kokeilun otos oli vain tusina ihmistä (Darrell Huffin ja jo mainitun kirjan mukaan). Tämä on juuri näyte, jota tarvitset saadaksesi tuloksia! Sanotaan, että käännämme kolikkoa viisi kertaa. Mikä on todennäköisyys, että laskeudut päähän kaikki viisi kertaa? (1/2) 5 = 1/32. Vain yksi kolmekymmentäkaksi, ei voi olla vain sattumaa, että kaikki viisi päätä nousee ylös, eikö niin? Kuvitellaan nyt, että toistamme tämän kokeen 50 kertaa. Ainakin yksi näistä yrityksistä onnistuu. Kirjoitamme siitä raportissa, ja kaikki muut kokeet eivät mene mihinkään. Siten saamme yksinomaan satunnaisia tietoja, jotka sopivat täydellisesti tehtäväämme.
Pelataan asteikolla
Oletetaan, että huomenna sinun on näytettävä kokouksessa, että olemme saaneet kilpailun kiinni, mutta numerot eivät lähennä toisiaan, mitä meidän pitäisi tehdä? Siirretään asteikkoa vähän! Jopa tunnettu New York Times, joka on tunnettu laadukkaasta datatyössään, on julkaissut tällaisen täysin sekavan graafin (huomaa hyppy 800k: sta 1,5m: iin asteikon keskellä). (esimerkki Howard Wainerilta. American Statistician, 1984.)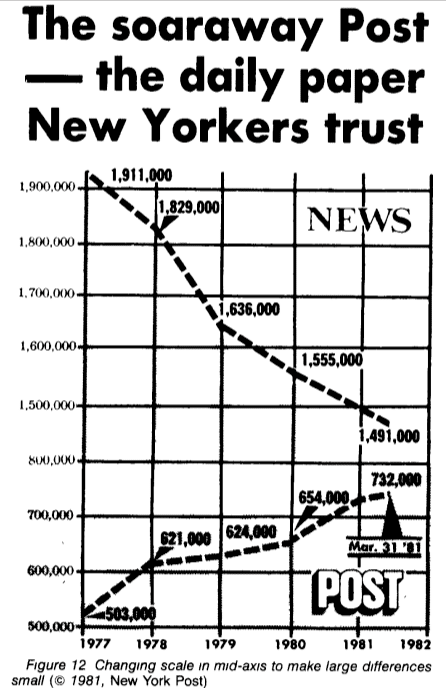
Valitsemme 100%
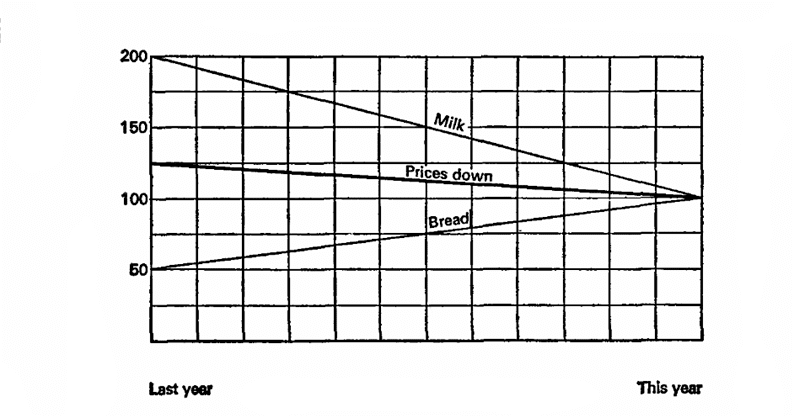
Kuvitelkaamme, että viime vuonna maito maksoi 10 kopiota litrasta ja leipä oli 10 kopiota leipää kohti. Tänä vuonna maidon hinta on laskenut 5 kopeikkaa ja leipä 20: llä. Huomio kysymykseen, mitä haluamme todistaa?
Kuvitellaan, että viime vuosi on 100%, laskelmien perusta. Maidon hinta laski sitten 50% ja leipä nousi 200%, keskimäärin 125%, mikä tarkoittaa, että hinnat yleensä nousivat 25%. Yritetään uudelleen, olkoon kuluva vuosi 100%, mikä tarkoittaa, että maidon hinnat olivat viime vuonna 200% ja leipä 50%. Tämä tarkoittaa, että viime vuonna hinnat olivat keskimäärin 25% korkeammat!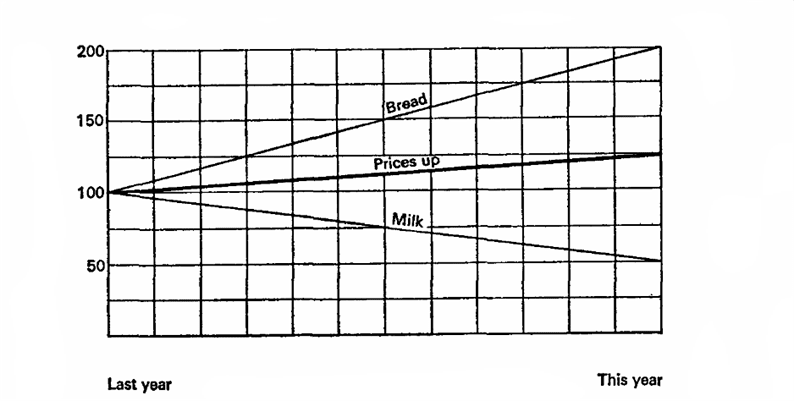
Kerää tietoja, jotka tekevät johtopäätöksistäsi entistä puolueellisempia
Ensimmäinen vaihe tilastojen keräämisessä on määrittää, mitä haluat analysoida. Tilastotieteilijät kutsuvat tässä vaiheessa tietoja väestöksi. Seuraavaksi sinun on määriteltävä alaluokka tietoja, joiden analysoituna tulisi edustaa koko populaatiota kokonaisuutena. Mitä suurempi ja tarkempi näyte on, sitä tarkemmat tutkimustulokset ovat.
Tietysti on olemassa erilaisia tapoja pilata tilastollinen otos vahingossa tai tahallaan:
- Valintaperuste. Tämä virhe tapahtuu, kun tutkimukseen osallistuvat ihmiset tunnistavat itsensä ryhmäksi, joka ei edusta koko väestöä.
- Satunnainen näytteenotto. Tapahtuu, kun helposti saatavilla olevaa tietoa analysoidaan eikä yritetä kerätä edustavaa tietoa. Esimerkiksi uutiskanava saattaa tehdä poliittisen kyselyn katsojiensa keskuudessa. Kyselemättä ihmisiä, jotka katsovat muita kanavia (tai eivät katso televisiota ollenkaan), ei voida sanoa, että tällaisen tutkimuksen tulokset kuvastavat todellisuutta.
- Vastaajien kieltäytyminen osallistumasta. Tällainen tilastovirhe tapahtuu, kun jotkut ihmiset eivät vastaa tilastollisessa tutkimuksessa esitettyihin kysymyksiin. Tämä johtaa virheelliseen tulosten näyttämiseen. Esimerkiksi jos tutkimuksessa kysytään: ”Oletko koskaan huijannut puolisoasi?” Tämän seurauksena näyttää siltä, että huijaaminen on harvinaista.
- Vapaa pääsy kyselyihin. Kuka tahansa voi osallistua tällaisiin kyselyihin. Usein ei edes tarkisteta, kuinka monta kertaa sama henkilö vastasi kysymyksiin. Esimerkkinä ovat erilaiset Internet-kyselyt. On erittäin mielenkiintoista ohittaa ne, mutta niitä ei voida pitää objektiivisina.
Valintapoikkeaman kauneus on, että joku, jostain, todennäköisesti suorittaa epätieteellisen tutkimuksen, joka tukee mitä tahansa teoriaasi. Joten etsi vain verkosta haluamasi kysely tai luo oma.
Valitse ideasi tukevat tulokset
Koska tilastoissa käytetään lukuja, näyttää siltä, että ne todistavat vakuuttavasti minkä tahansa idean. Tilastot perustuvat monimutkaisiin matemaattisiin laskelmiin, jotka väärin käsiteltyinä voivat johtaa täysin vastakkaisiin tuloksiin.
Tietojen analysoinnin puutteiden osoittamiseksi englantilainen matemaatikko Francis Anscombe loi Anscombe-kvartetin. Se koostuu neljästä numeerisesta tiedosta, jotka näyttävät täysin erilaisilta kaavioilta.
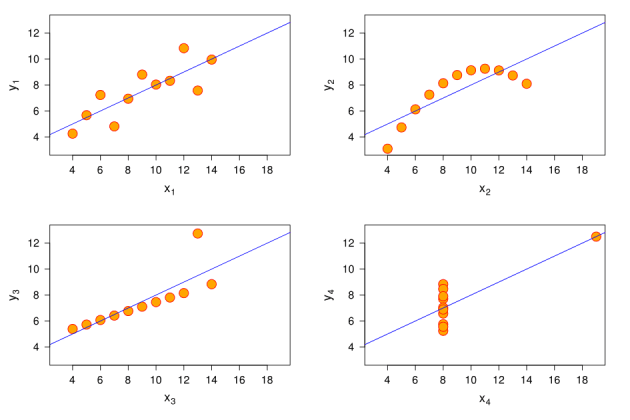
Kuvio X1 on tavallinen sirontakaavio; X2 on käyrä, joka ensin nousee ylös ja putoaa sitten alas; X3 – viiva, joka nousee hieman ylöspäin, yhden ylityksen Y-akselilla; X4 – X-akselin tiedot, lukuun ottamatta yhtä ylitystä, joka sijaitsee korkealla molemmilla akseleilla.
Seuraavat lauseet ovat totta jokaisen kaavion kohdalla:
- Kunkin tietojoukon x: n keskiarvo on 9.
- Kunkin tietojoukon y: n keskiarvo on 7,5.
- X-muuttujan varianssi (hajonta) on 11 ja y-muuttuja on 4,12.
- Kunkin tietojoukon muuttujien x ja y välinen korrelaatio on 0,816.
Jos näemme nämä tiedot vain tekstimuodossa, luulemme, että tilanteet ovat täysin samat, vaikka kaaviot kumoavat tämän.
Siksi Enscombe ehdotti, että visualisoit ensin tiedot ja vasta sitten teet johtopäätökset. Tietenkin, jos haluat johtaa jotakuta harhaan, ohita tämä vaihe.
Luo kaaviot, jotka korostavat haluamasi tulokset
Useimmilla ihmisillä ei ole aikaa tehdä omaa tilastollista analyysiään. He odottavat sinun näyttävän heille kaavioita, joissa on yhteenveto kaikesta tutkimuksestasi. Hyvin suunniteltujen kaavioiden tulisi heijastaa todellisuuteen sopivia ideoita. Mutta he voivat myös korostaa tietoja, jotka haluat näyttää.
Jätä pois joidenkin parametrien nimet, muuta koordinaattiakselin asteikkoa hieman, älä selitä kontekstia. Joten voit vakuuttaa kaikki, että olet oikeassa.
Piilota lähteet kaikin keinoin
Jos mainitset avoimesti lähteesi, ihmisten on helppo tarkistaa havainnot. Tietenkin, jos yrität saada kaikki sormesi ympärille, älä koskaan kerro, kuinka päädyit johtopäätöksiisi.
Yleensä artikkeleissa ja tutkimuksissa viitataan aina lähteisiin. Samanaikaisesti alkuperäisiä teoksia ei välttämättä toimiteta kokonaisuudessaan. Tärkeintä on, että lähde vastaa seuraaviin kysymyksiin:
- Kuinka tiedot kerättiin? Haastateltiinko ihmisiä puhelimitse? Vai pysäytettiinkö se kadulla? Vai oliko se Twitter-kysely? Tietojen keräämismenetelmä voi osoittaa tiettyjä valintavirheitä.
- Milloin he tapasivat? Tutkimus vanhenee nopeasti ja suuntaukset muuttuvat, joten tiedonkeruun ajoitus vaikuttaa johtopäätöksiin.
- Kuka ne keräsi? Tupakointiyrityksen tupakoinnin turvallisuutta koskevassa tutkimuksessa on vain vähän uskottavuutta.
- Ketä haastateltiin? Tämä on erityisen tärkeää yleisen mielipidekyselyn kannalta. Jos poliitikko tekee kyselyn hänen kanssaan sympatisoivien joukossa, tulokset eivät heijasta koko väestön mielipidettä.
Kuinka valehdella tilastojen avulla – osa 2
Analysoimme edelleen, kuinka voit johtaa ihmisiä harhaan käyttämällä väärin tilastoja. Edellinen viesti
Keskitasoinen valinta
Voit usein kuulla sanan ”keskiarvo” uutisissa ja mainoksissa. Mutta mitä tarkoittaa? On aritmeettinen keskiarvo, geometrinen keskiarvo, harmoninen keskiarvo ja luettelo jatkuu! Epäasianmukainen (vahingossa tai tarkoituksella) keskiarvon valinta voi vääristää tuloksia merkittävästi.
Tarkastellaan esimerkkiä. Oletetaan, että meillä on kolme ihmistä: isoäiti Elena Anatolyevna 8000 eläkkeellä, järjestelmänvalvoja Vasya 40 000 palkalla ja miljonääri Pavel Umnov, joka ansaitsee tasan miljoonan kuukaudessa
Jos laskemme yksinkertaisesti aritmeettisen keskiarvon lisäämällä heidän palkkansa ja jakamalla 3: lla, saamme, että se on 350 tuhatta ruplaa! Jää vielä miellyttää isoäitiä tämän uutisen kanssa
Logaritmisella asteikolla nämä arvot eivät edes näytä liian kaukana toisistaan. Punainen viiva – aritmeettinen keskiarvo
Tällaisissa tapauksissa mediaanin kaltainen keskiarvo sopii paremmin. Tämä on arvo, joka jakaa kaikki tietomme kahteen yhtä suureen osaan (määrän mukaan). Tämän esimerkin mediaaniarvo olisi järjestelmänvalvojan Vasyan palkka – 40 000. Ennen häntä ja sen jälkeen on sama määrä ihmisiä (yksi kerrallaan). Sitten voisimme kutsua Vasya henkilöksi, jolla on keskipalkka, jokainen, joka saa vähemmän kuin Vasya – pienillä tuloilla, enemmän – rikkaille.
Mediaanin avulla olisi kuitenkin päinvastoin mahdollista piilottaa hyvin näkyvät (ylös tai alas) arvot
Taittamaton taittamaton
Ajattele viiden pisteen luokitusjärjestelmää koulussa. Kuvittele, että seitsemännen luokan oppilas Danil kirjoitti sanelun viidelle, ja hänen luokkatoverinsa Leonardo päätti kirjoittaa sen oikealta vasemmalle ja sai kaksi. Jaamme 5 kahdella ja saamme, että Danil kirjoitti sanelun 2,5 kertaa paremmin! Eikö?
Väärä. Pisteet ovat keksitty nimellinen muuttuja, joka ilmaisee numeerisesti sanallisia arvosanoja erinomaiset, hyvät ja niin edelleen. Onko ”epätyydyttävä” täsmälleen 2,5 kertaa huonompi kuin ”erinomainen”?
Siksi ei ole matemaattisesti merkityksellistä laskea arvosanojen tai minkään testin keskimääräisiä pisteitä.
Puolueellinen näytteenotto
Internet-äänestystietojen mukaan 100% ihmisistä käyttää Internetiä
Voit valehdella ennen tilastoja, jos keräät tietoja väärin. Klassinen esimerkki on Yhdysvaltain vuoden 1948 presidenttikisa: Dewey vs. Truman. Chicago Tribune suoritti kyselyn heti äänestyspaikkojen sulkemisen jälkeen ja kutsui valtavan määrän ihmisiä. Tulosten mukaan ennustamalla mahtavaa menestystä Dewey julkaisi sanomalehden otsikolla ” DEWEY voittaa Trumanin ”. Kuvassa näkyy naurava Truman, vuoden 1948 vaalien voittaja, juuri tämän sanomalehden kädessä
Jotain meni pieleen? Sanomalehti soitti otokseen riittävän määrän äänestäjiä ja todellakin satunnaisia. Ainoastaan lähestymistapa itsessään oli väärä – köyhän väestön käytettävissä ei ollut tuolloin puhelinta, josta suurin osa oli Trumanin tukea.
Toinen esimerkki on yliopistojen lupaamat valmistuneiden palkat. Yhdysvalloissa se meni jopa tuomioistuimiin – tutkinnon suorittaneet väittivät, että palkkatiedot olivat keinotekoisesti paisutettuja. Mutta asia on täysin erilainen: vain ihmiset, jotka ovat tyytyväisiä heihin, jakavat tietoja tuloistaan yliopiston kanssa.
”Visuaalinen” visualisointi
On tuhat yhtä tapaa kaunistaa tietoja. Esimerkiksi visualisoi ne visuaalisesti. Se voi auttaa lukemaan tylsiä kaavioita, ja jos se tehdään vähän temppuilla, on kannattavampaa esittää ne.
Tässä on kaavio Yhdysvaltojen oluen kulutuksesta miljoona tynnyriä ja Schlitzin osuus. Hän on todella vaikuttava!
Mutta laitetaan tämä kaavio tiukempaan muotoon: näytä tiedot pisteillä ja aloita y-akseli nollasta:
Ei tunnu enää niin vaikuttavalta. Piirrettäessä kuvaajan pisteitä tynnyreinä, ihmiset eivät visuaalisesti havaitse tynnyrien yläosaa, vaan niiden määrää. Ja kun tynnyrin sivua suurennetaan 2 kertaa, äänenvoimakkuus kasvaa 8 kertaa! Tällaisessa mittakaavassa y-akseli, joka alkaa arvosta 100, auttaa.
Tässä on toinen esimerkki. Upeat infografiikat, jotka osoittavat, kuinka paljon rahaa käytetään tautien ja niistä johtuvien kuolemien torjuntaan
Idea on hieno. Katsokaa kuitenkin tarkemmin numeroita. Hinta oranssilla ympyrällä on noin 2 kertaa pienempi kuin vaaleanpunaisella. Mutta vaaleanpunainen ympyrä on 4 kertaa suurempi!
Kirjoittajat halusivat tehdä ympyrän säteen hinnasta riippuvaisen. Mutta visuaalisesti ei havaita lainkaan sädettä, vaan kuvan pinta-alaa! Ja ympyrän pinta-alan kaava riippuu säteestä neliöllisesti
Tätä infografiaa voidaan tehdä vieläkin paremmaksi sijoittamalla samat sairaudet samalle riville. Tarkistettu versio näyttää tältä:
Visualisointi ei ole pelkästään uskottavampaa, vaan se myös selkeästi välittää ajatuksen: jotkut sairaudet eivät ole niin vaarallisia kuin niihin käytetään rahaa, ja taistelu toisia vastaan on alirahoitettua.
Esimerkki korkealaatuisesta visualisoinnista
Kaavio näyttää Napoleonin armeijan koon. Äärimmäinen oikea kohta on Moskova, josta vetäytyminen alkaa, mustalla raidalla. Aika- ja lämpötilakaavio on myös linkitetty vetäytymisohjelmaan. Erittäin selkeä!
Tietoja Darell Huffin kirjasta ”Kuinka valehdella tilastojen avulla”
Tässä maailmankuulussa kirjassa Darell Huff käsittelee erilaisia tapoja, joilla tilastoja käytetään väärin yleisön pettämiseen ja manipulointiin. Joka päivä he yrittävät vaikuttaa sinuun kannustaakseen sinua ostamaan jonkin ”tarpeellisen” tuotteen tai valitsemaan ”oikean” ehdokkaan: ”” Clean Teeth ”-pastan ansiosta karieksen muodostuminen vähenee 23%!”; ”85% kansalaisista tukee N-politiikkaa” … Kuinka ymmärtää kuinka luotettavat tietyt tiedot ovat? Kuinka laskelmat ovat? Mikä otetaan huomioon ja mikä on kulissien takana? Kirjoittaja paljastaa tilastojen salaiset työkalut ja varustaa lukijalle tietoa, joka auttaa ymmärtämään tämän tieteen kaikki monimutkaisuudet eikä salli sekaannusta.
merkintä
Tässä maailmankuulussa kirjassa Darell Huff käsittelee erilaisia tapoja, joilla tilastoja käytetään väärin yleisön pettämiseen ja manipulointiin. Joka päivä he yrittävät vaikuttaa sinuun kannustaakseen sinua ostamaan jonkin ”välttämättömän” tuotteen tai valitsemaan ”oikean” ehdokkaan: ”” Clean Teeth ”-pastan ansiosta karieksen muodostuminen vähenee 23%!”; ”85% kansalaisista tukee N-politiikkaa” … Kuinka ymmärtää kuinka luotettava tämä tai toinen data on? Kuinka laskenta tehdään? Mitä otetaan huomioon ja mikä jää kulissien taakse? Kirjoittaja paljastaa tilastotieteilijöiden salaiset työkalut ja antaa lukijalle tietoa, joka auttaa ymmärtämään tämän tieteen kaikki monimutkaisuudet eikä anna sinun johtaa harhaan.
Käytetyt lähteet ja hyödyllisiä linkkejä aiheesta: https://habr.com/ru/post/217545/ https://Lifehacker.ru/4-sposoba-lgat-pri-pomoshhi-statistiki/ https://pikabu.ru / story / kaklgat_s_pomoshchyu_statistiki_chast_2_6113007 https://lifeinbooks.net/chto-pochitat/kak-lgat-pri-pomoshhi-statistiki-darell-haff/ https://coollib.net/b/331961-kat-plgat-